The present proceedings in the Supreme Court on the Constitutionality of the DPDPA raise several issues of concerning the relationship between informational privacy, transparency in governance and the regulatory framework governing digital personal data.
The most contentious provision which is being discussed is the Section 44(3) which is sought to be repealed.
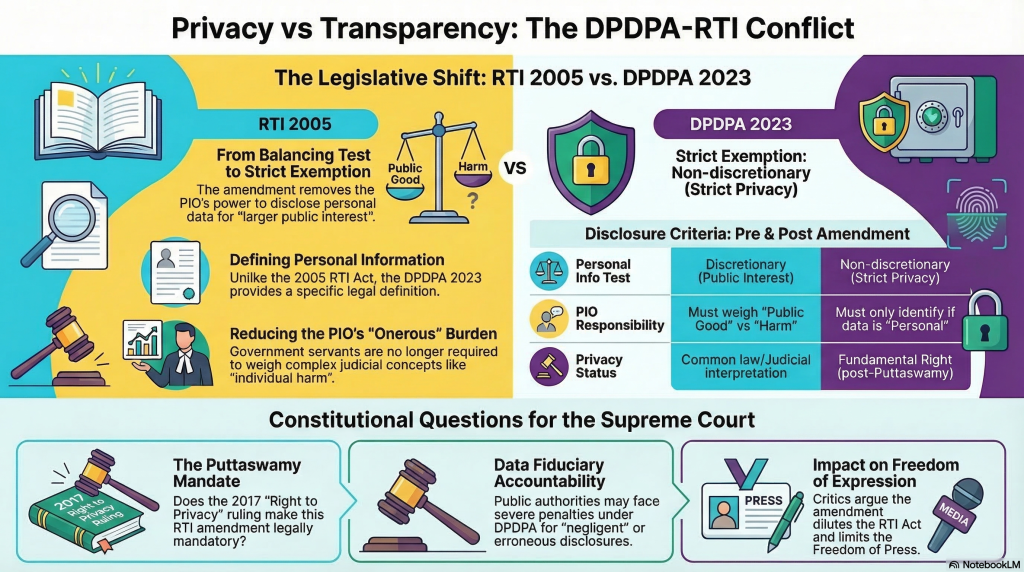
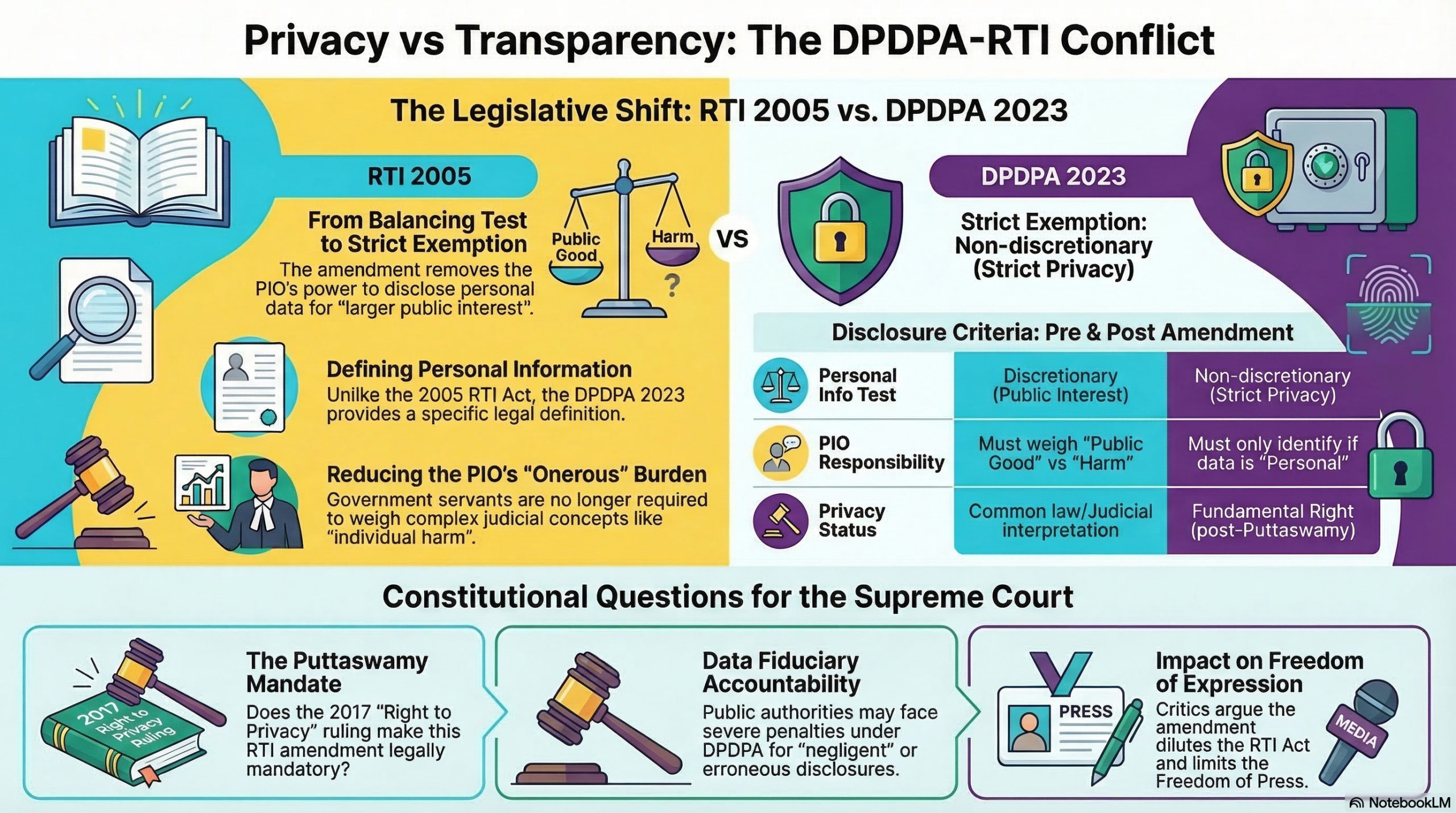
The objection is that the current provision which is stated below has stood the test of time and the proposed provision dilutes the RTI Act and consequently the “Right to Freedom of Expression” as well as the “Right to Freedom of Press”.
Pre-Amendment Section:
matters which come under the exemptions specified in this section shall not be disclosed
– information which relates to personal information the disclosure of which has no relationship to any public activity or interest, or which would cause unwarranted invasion of the privacy of the individual unless the Central Public Information Officer or the State Public Information Officer or the appellate authority, as the case may be, is satisfied that the larger public interest justifies the disclosure of such information:
Provided that the information which cannot be denied to the Parliament or a State Legislature shall not be denied to any person.
Amended Section:
– information which relates to personal information
In the current provision the PIO was expected to take a view on whether the information is of personal nature and if so whether it infringes certain rights of Privacy. In the amended section, the PIO has to only identify if the information is personal or not.
What is personal information is defined in the DPDPA 2023 which was not in existence when RTI act of 2005 was enacted.
What is “Privacy” and how it can be “Infringed”, what is the “Harm” caused, “What is the weight of public good vs individual harm” are not defined and remain vague. Expecting the PIO to decipher this is an unfair burden on a Government servant. Even the Courts will find it difficult to provide specific answers to these questions. Hence such questions can only be resolved in a subsequent appeal in a Court of law.
Also the declaration of “Right to Privacy” as a fundamental Right is a development after the Puttaswamy judgement and till then the MP Sharma Judgement and Kharak Singh Judgements prevailed. They did not hold that Right to Privacy included “Information Privacy” and it was a “Fundamental Right”. Hence after 24th August 2017, there was a need to amend Section 8(1)(j) of the RTI act and that obligation has been fulfilled by Section 44(3) of DPDPA 2023.
Hence Section 44(3) is a direct mandate of the Supreme Court judgement in Puttaswamy case and cannot be altered by any bench of less than 9 members.
Hence during the Supreme Court trial starting from March 23rd or later, the following questions of law arise for consideration by the Court:
- Whether after the 9 member SC bench in the case of Justice Puttaswamy judgement (2017) declaring that “Right to Privacy is a fundamental Right”, can the provisions of RTI Act, Section 8(1)(j) was mandatorily required to be amended.
- Whether the requirement under the old Section 8(1)(j) of RTI Act was an onerous judicial obligation cast on the PIO to determine
- whether the information sought to be released has no relationship to any public activity or interest, or
- Whether the information sought to be released would cause unwarranted invasion of the privacy of the individual
- Whether the information sought to be released is in the larger public interest justifies the disclosure of such information
- Whether the information sought to be released can be or cannot be denied to the Parliament or a State Legislature
- If the RTI disclosure is considered under Section 8(2), Whether a public authority can take a judicially appropriate decision on the disclosure outweighing the harm to the protected interests.
- If the PIO errs in such judgement and discloses information, whether the public authority as a “Data Fiduciary” be held accountable for the penalties under Section 33
- Whether the PIO being generous in disclosure can be held “Negligent” and penalized for incompetence?
- Whether in such cases, the RTI applicant can be expected to Provide an assurance
- that to the best of his belief and knowledge, the information sought to be released does not infringe the privacy of any other individual,
- the possible harm caused to any individual/s outweighs the larger public interest in the disclosure
- the applicant indemnifies the public authority and the PIO of any harmful impact of penalties under section 33 of DPDPA 2023
- Should only a DPO be designated as the PIO since credentials required to be a PIO are less stringent than that of a DPO?
We want Constitutional pundits to answer these questions.
Naavi
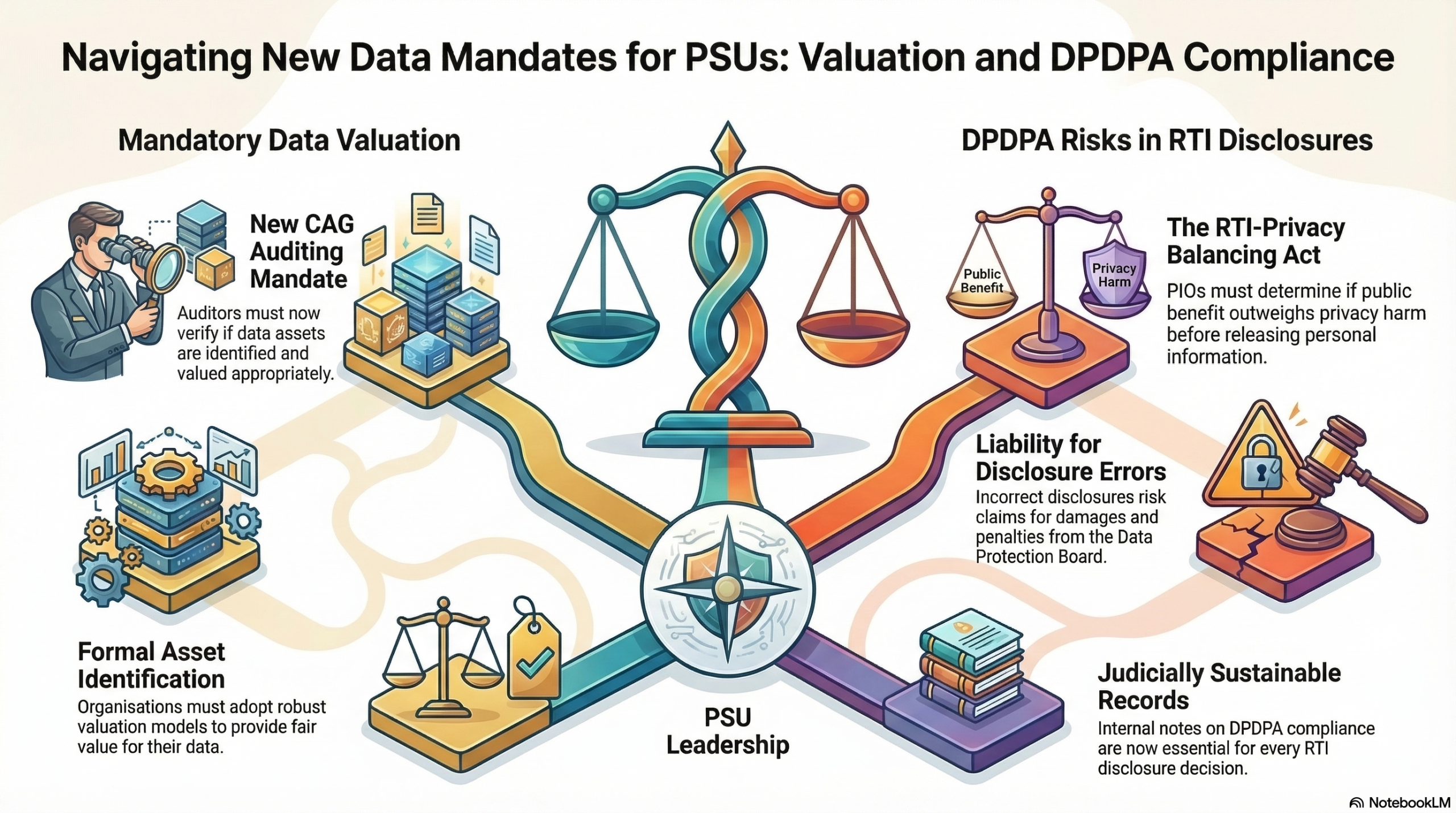
 These highlighted the need for PSUs to adopt a Data Valuation model since CAG has given a direction to the Auditors to answer the query “whether the Company has identified its data assets and whether it has been valued appropriately”.
These highlighted the need for PSUs to adopt a Data Valuation model since CAG has given a direction to the Auditors to answer the query “whether the Company has identified its data assets and whether it has been valued appropriately”.




")


