[Discussions here are part of the Naavi’s Theory of Data]
Data Governance in an organization requires identification of what is data, how data can be created or collected, what is its value, who is the custodian, who is the owner, who will have access?, What are the permitted uses?, What are the permitted ways of modification that creates new data assets, how the data can be shared or how it can be destroyed.
A detailed discussion of these are part of Naavi’s discourse on the Theory of Data for an academic discussion at some other time.
We have already discussed the concept of “Nuclear theory of Data” in the context of personal data in the following articles.
1.Fission and Fusion of data elements
In the recently released Draft India Data Accessibility and Use policy, the Government has set an objective to draw up an inventory of data assets in each of the Ministries and Departments and in this context, I would like to place a discussion on how do we classify “Non Personal Data” in a similar atomic model.
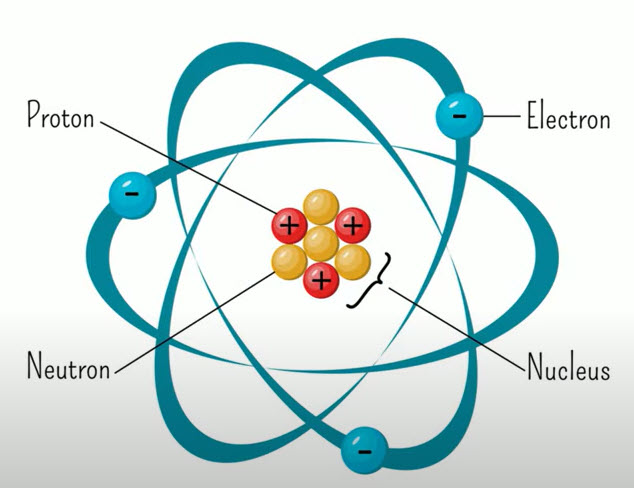
The “Atomic Model” of data envisages that
-
- There is a core element of identity of the data
- There are peripheral associate elements that give depth and width to data
In the Personal data context, the Name is like the proton but does not constitute a stable atom on its own. If it is associated with another stabilization element such as say the Aadhaar number or PAN card or Social Security number which gives a “Unique Identity” atleast within a large enough universe (Eg: Aadhaar is a unique identity in India but may not be considered so in another country). This combination of the Name and one or more unique identity factors form the nucleus. But Nucleus alone does not give the property of the atom. We need a set of electrons that revolve around like the other information such as the email address or mobile number etc which together give shape to the data set as a stable atom. When two such atoms combine together there can be a molecule and when more molecules get bonded, we may get a compound or a complex organic molecule.
In the non personal data, (NPD) defining a data set requires identification of a core identity element for the data set and then the associated information. NPD does not have the name of an individual to whom the data relates. But it could have an “event” or an “Object” to which the data relates. For example, data about a company or about a market research or about a cricket match are “NPDs but related to a core activity or object”. This core object is the defining sub atomic particle of the NPD element.
The depth and width of the element is determined by how may neutron like core elemental particles and how many electron type peripheral particles are associated.
A NPD data set can be a PDF document or a video or an entire data base. A document about a cricket match or a video about the same cricket match can eb considered as two distinct data sets. They can be combined with information on several cricket matches in a data base in which case the data base is an NPD set.
When an inventory is being created, we need to identify and define the data set, give it an identity tag so that it can be accessed by users. In such an inventory, the data set has to exist in some stable form such as a video clip of atleast a few seconds for the data to have any meaning. The PDF document and the Video clip can be considered as stable data sets. They can be included in a data base an access may be defined either to specific stable elements or to a larger document depending on the requirement.
When a search facility need to be created, the search term has to be for a stable data element. For example, while we can do a text search for “sta” and index it, the more useful search term would be “stable”. Similarly the “Searchable component” of a data set could be such a term that can be useful to the person trying to locate the document.
These concepts need to be debated and refined further to enable “Data Governance” around “Non Personal Data Sets” generated, created, collected, used, disclosed and destroyed by an organization whether it is a Government department or a Private Company.
Industry representatives may comment if this concept has any relation to the way they define a data set under their control for Data Protection requirements under GDPR or other similar laws.
Naavi
Reference Articles:
Atomic model of Data
Fission and Fusion of Data




")


