“Personal Data” is the object of data protection regulations such as the upcoming Data Protection Act of India, the DISHA 2018, as well as other laws such as GDPR and ITA 2008. “Protecting Personal Data” is considered “Information Privacy” by the Indian judiciary which declared “Privacy as a fundamental Right”. In all the data protection regulations, Data is classified as “Personal Data” and “Sensitive Personal Data (or special category personal data)” and different responsibilities are prescribed to the Data Controllers and Data Processors.
The current global controversy on Face Book being responsible for its customer’s profiles being used for influencing US elections is an interesting case study for examining the efficacy of the current data protection laws and where the laws have failed to capture the real nature of data and are therefore failing in the implementation of the data protection laws. If laws are failing in the current scenario, they will be failing more often when we consider the emerging era of Big Data Analytics, Artifical Intelligence and Quantum Computing.
While ITA 2008 and GDPR are already frozen, India has two data protection regulations in the pipeline namely the DISHA 2018 (Digital Information Security for Health Care Act) and Data Protection Act of India as being drafted by the Justice Srikrishna Committee. It is therefore a great opportunity for the Indian legislators to incorporate certain new provisions of data protection that other legislation including GDPR might have missed. Naavi has already provided some inputs on the proposed laws in earlier articles.
Theory of Dynamic Personal Data
This article will however introduce a new “Theory of Dynamic Personal Data” which if recognized and brought into our regulations may resolve some of the anomalies which we are presently facing.
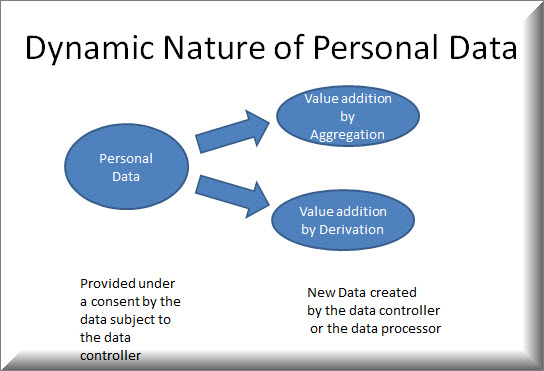
The basic concept of this theory is that “Personal Data” is dynamic. It is not a static concept where one entity collects it under a “Consent” and uses it for a stated purpose and just destroys it afterwards.
Data once created cannot be easily destroyed. It can only be converted into another form where it looks different. It is therefore like “Energy” that cannot be destroyed in the universe but can only be converted from one state to another.
Energy can even be converted from being a “Particle” or a “Wave”. Similarly Data can be converted into a tangible “Document” or seen as “binary impressions on a magnetic or optical media”.
In the Quantum computing theory, “Data” can be in the form of Qubits with an uncertain state of being either a Zero or One but assuming a probabilistically determinable value when measured.Same “Uncertainty” can be there in the state of “Personal data” also even in the classical computing environment.
Data has a life cycle in which it is generated, re-generated, processed into a value added form, fused and fissioned, deleted and undeleted, forgotten and remembered, used and misused, de-identified or anonymized or pseudonomized and re-identified.
Hence any data protection law which assumes that an “Informed Consent” from the data subject to the first data collector will solve all the problems of “Information Privacy” is a complete myth.
What is required is for the law to recognize that “Personal Data is dynamic in nature” and at any given point of time it exists in a certain state of uncertainty. It can however be measured at a specific point of time when it shows up in a certain form. This is exactly similar to the “Uncertainty Principle” embedded in the “Superpostioning” concept of the Quantum computing.
Three Fundamental Rules of Dynamic Data Theory
We can define three fundamental rules of Dynamic Data Theory for further discussions
The first rule is that
“Personal Data does not exist in isolation but exists in the Data Universe”.
Such data universe consists of
-the data subject’s data in different forms with different data controllers, collected at different times, along with
-many versions of the personal data processed by different processors for different purposes and
-combined with the data of other data subjects.
The second rule is that
“Personal Data exists in an uncertain state where it may be personal or non personal, sensitive or otherwise and assumes a certain state at the time of its measurement.”
The third rule is that
“Personal Data is not “Absolute” in truth and accuracy and always exists in a form dependent on the context of its collection and use.”
How these rules should be integrated to law making
Let us now elaborate on these three rules and discuss why a data protection law that does not consider these rules is defective ab-initio.
We define “Personal Data” as that information that is identifiable with a living person. Obviously, Name is the primary identifier for an individual in the physical world. In the Cyber world, it is the e-mail ID or an Avtar ID that substitutes the name as the real identity of a Netizen.
Address in the physical world, the IP address in the cyber world are also identifiers.
Additionally, there could be other parameters such as the Mobile Number, the Aadhaar number, PAN number, the Voter’s ID etc which are all different identity parameters.
There are also additional parameters such as the age, sex, political affiliation, sexual preference, the health information, the financial information etc that are also considered “Personal information” when they are identifiable with a living individual.
The basic or “Primary” personal information is not the health or financial information but the physical identity information such as the name and address or the cyber identity parameters such as the biometric or password. Other information may be important but they are “Secondary Personal Information”.
So far, no law has defined “Primary Personal Information” and “Secondary Personal Information”. We have jumped from “Personal Information” to “Sensitive personal information” without clearly defining which is “Primary” and which is “Secondary”.
In the personal data cycle, “Personal Information” starts with the “Birth Certificate” which defines the name of an individual along with that of his parents, place of birth, date and time of birth. This is the “Primary Personal Information” at the atomic state. Within this, it is difficult to determine which comes first and which comes later.
In olden days, birth certificates used to be issues as “Son/daughter of X, the father and Y the mother”. The name actually came later as an assignment by the parents in the naming ceremony. However, convention today is to issue a “Birth Certificate” incorporating the assigned name. Hence the parameters of the birth certificate namely the Name, data of birth, place of birth, name of father and mother, is the atomic level personal information that needs to be defined as “Primary Personal Information”.
Subsequently other information about the data subject gets added including the record of the DNA profile or blood group etc. Further the education, employment particulars, bank particulars, other health parameters all get added to the “Personal Information”.
What we need to recognize here is that “Personal data changes its state on a continuous basis” though it may appear from time to time in the form of a snap shot which is the electronic document such as PAN card or Aadhaar card, Medical report, Bank statement etc.
Hence law has to define “Personal Information” as an “Evolving set of data that gets tagged to the Primary personal information created with the birth certificate parameters”. It is only the birth certificate parameters that can be frozen as an “Electronic Document defining the personal Information of an individual” and this gets extinguished with the “Death Certificate”.
In between, even the name of the person may change if the person so desires. His age ticks every second, his health data and financial data changes every moment. If therefore we want “Personal Data to be accurate” as a legal requirement, the personal data record has to be updated every moment which is not feasible.
It is in this context that I say that “Personal Data is in an uncertain state” and only when you want to measure it, you try to get a health report or a bank report where the personal data is frozen at a given point of time and place. This is the “Superpositioning Nature of the personal Data” similar to the Quantum computing scenario. While the Quantum super positioning can assume either Zero or One, the Personal Data is a “Continuum” of many states and is changing all along.
In this context, personal data of a person exists in a “Data Universe” where new data gets generated and some of the new data gets tagged with the Personal ID of the data subject and we say that “Personal Data has changed”. But this change of data can be recognized only of the Data Controller becomes aware of the change.
If a data subject shares his data with one data controller on 1st January 2018 and with another data controller on 31st January 2018, the two will be different. Each will be using the data based on the consent obtained and processing it and deriving inferences as if they know the truth. If the data subject says he will vote for BJP on January 2018 then he will be classified as a BJP oriented person. If on January 31, he says he will vote for Mr X from Congress who is the local candidate in the forthcoming election, the data changes colour and makes him a Congress supporter.
If both data is available to a single data processor he will compute a data analytic report showing the trend that this voter is changing his profile and the trend is that he is moving from BJP to Congress. If before the election, Modi makes a speech the trend may change again.
In such a scenario, the “Profiling” remains uncertain. Hence the so called “personal data” which includes the political affiliation is just an interpretation by a data processor with the available information on hand and his own skill in interpretation and it is not an absolute truth that the person is either a BJP supporter or a Congress supporter.
Without understanding the three rules, if law tries to say “No body shall use personal data except as provided by a consent”, then one has to question “Which data are we talking about”?
Is it the direct data that is provided by the individual once that he is a BJP supporter and another time as a Congress supporter? or
Is it the “Processed Data” that says that the person is an undecided voter and may change his preference based on the stimuli he receives closer to the election?
If an analyst like Cambridge Analytica comes to a conclusion, and develops a “Profile Report”, should the law consider this as a “Primary or Secondary Personal data” provided by the data subject or a “Derived Information” that is not necessarily guaranteed as the true and absolute personal information but is only an expert’s view of the analysis.
If so, should the data anlaytics firm be punished for data breach if it shares its analysis with a candidate who is trying to finalize his communication strategy? is a question which the law makers need to answer.
Today, the law makers say that all these decisions will be decided by the “Consent”. According to them they feel… “Let the person collecting the consent get the consent for processing it, deriving meanings and then sharing it with some body else for profit or for a cause etc.”
However at the time of obtaining a consent, the data controller only has a limited view of what information he is getting and how he may use it. But due to the “Dynamic nature of the data”, after collection, the data in the hands of the data controller “Grows”, “metamorphoses” into a different form and he discovers that he can now make new uses of the data.
What he bought was perhaps a caterpillar and now it has become a butterfly.
Should the law now say, go back to the data subject and ask him if he can use the butterfly instead of the caterpillar? . Of course law can say so.. because law can be an ass.
But what we need to ask the law makers is whether we can create a law which recognizes that the data which looks to be a caterpillar today may die as a caterpillar or change into a beautiful butterfly and we should encourage the data holder to nurse the caterpillar in any way the data controller wants and make it more valuable than what it was when it was handed over by the data subject. This is the business of Data mining and data analytics on which a huge part of the IT industry is standing today.
Another complication in the data scenario is that data may be processed by a number of down stream data processors and today we define due diligence at each level in the form of a “Consent” or “Processing Contract” which can only capture known information about the data and not what can be “Discovered”. Also, down stream data processors are not aware of the original consent and have to proceed with their processing only on the basis of the data processing contract as provided to them by the Data collector.
If data protection laws try to curb the “Discovery”, of new uses of data, we will be curbing scientific development and the concept “Data is the New Oil” would be killed to the detriment of the progress of the society.
If therefore Mr Aleksandr Kogan created some inferences based on the data he obtained by from Face Book users under a separate consent given on his APP, then the inference he derived was a “Derived Data” and not “Absolute Personal Data” of the data subject.
Presently the community is fighting over the issue as if “Personal data” has been breached. But actually what has happened is that some body created a notional value addition and some body paid money to buy it. It is a total speculation that it was beneficial to Mr Trump and whether similar analysis in India will benefit BJP or Congress, no body knows.
The “Dynamic Personal Data” theory breaks the guardian knot and releases the “Processed Data” from the constraints of the “Consent on the raw data”.
In other words, the consent obtained for transferring the cater pillar is not allowed to restrain the use of the Butterfly.
Quantum States of Personal Data
When personal data is in the hands of one data processor, it is in a certain state of certainty defined by the information obtained under the “consent”. But while the data is being put to use, it slowly gathers energy and becomes more and more useful with additional information flowing in from a different source and from a different person.
For example, one person in a certain street address says that he likes to vote for BJP. Then let us say another piece of data that the person attended a BJP rally or a BJP team visited him at his house and had a discussion gets added to the data base. Now the first information gets hotter and hotter until the analyst of the data comes to a conclusion with his algorithm that this is a BJP voter and profiles him as such.
In this example, we can see that a “Personal Information” attains the status of a “Sensitive personal information” without the data subject doing anything or providing any additional information by himself. Same thing may happen when the Google map adds data that this data subject visits a dialysis center every week and the inference is that he is a kidney patient. If this data is looked along with the financial information of the data subject, one can infer if he is a prospective candidate for accepting kidney donation.
This sort of movement of Personal information from one state to another after accumulation of additional data from the Big Data platform or by his own contribution is like the “Quantum Jump” of an electron rendering the atom state change. If the incoming data energy is less than the quantum requirement, it increases its entropy but remains a “personal information” only. But when the entropy level crosses a certain quantum level, the data changes its status. If the data energy is strong enough then it is not only the electron that makes a quantum jump but the nucleus itself may go into fission and change the entire profile of the data. In the Cambridge Analytica case, if the advertising input is strong enough then the profile of the data subject may alter from a BJP supporter to a Congress supporter or vice versa.
Now according to present data protection laws, the information which was earlier only a “personal information” got fused with other information such as “BJP party activity in the areas” and the result was a “Political profiling” of the data subject which is “Sensitive personal information”. As it is now happening, data privacy activists will say this is an inappropriate use of the consent for manipulating the voter behaviour and should not be allowed.
But is this change of status “Controllable” by law stating that you cannot bombard the data subject with additional information? . If done, are we trying to curb the business of advertising and communication itself? is a point that the data protection laws need to address before jumping to introducing stringent data protection laws in the light of the Face Book -Cambridge Analytica issue.
Thus we need to remember that Data is not static. It grows with the accumulation of additional data from the surroundings. In the process data changes colour and renders the earlier consent meaningless in the new scenario.
Similarly, non personal data can become personal data when there is fusion of identification parameters and an identifiable personal information may become de-identified personal information if the identity parameters are removed.
The Data Protection law in the next generation cannot be blind to this aspect of “Dynamic State of Personal Data” and should not create laws with the assumption that personal data always remains in a static form until the data subject himself provides new data inputs with new consents etc.
Is it a Diamond or Charcoal?
In this process of Data Transition through its life cycle, the value of data may change substantially. Just as Carbon can exist both as charcoal or diamond based on how it is processed, Data can remain worthless or become valuable depending on the processing.
If data processing creates a diamond,
should we stop such processing because the charcoal supplier supplied it at a throw away price thinking that it will be used for burning and gave his consent for its use while the processor applied technology to compress the charcoal and discovered a means of converting it to diamond?
or
should we mandate that all data subjects will get royalty when their personal data will be used to create profits to the down stream industries?..
is a challenge that the data protection law makers of India need to consider when they draft the new laws.
Naavi
Reference Articles:
Uphold the “Right to Know” against “Right to Privacy” in the new Data Protection Law
We should forget the “Right to Forget” in Indian Data Protection Act
Cambridge Analytica and Indian Cyber Laws
Personal Data should be considered a personal Property
Public Consultation on Data Protection Legislation
Public Consultation on Data Protection Law…. Some points of discussion : Part I, Part I, Part III
Why We need a Data Breach Protection Act rather than Data Protection Act
CCTV footages.. Whose property is it any way?
Impact of Supreme Court’s Order on Right to Privacy on Cyber Space and Data Protection
Concatenating the individual Conclusions of the Privacy Judgement
Data Protection Act.. We should aim at Compliance with Pleasure not Compliance with Pain.
Look beyond GDPR and Create Personal Data Trusts to manage Privacy of data subjects
Privacy law cannot be only a tool for hiding oneself
Earlier innovative theoretcial Thoughts of Naavi
“Theory of Secure Technology Adoption”… what it is..
Section 65B and its relation to the Theory of Soul and Body, rebirth and past life memory
The Three Plus One dimensions of Information Security
Fighting susceptibility for “Cyber Hypnotism” with Ulysses Contracts




")



Whew ! What an insightful article ! I genuinely enjoy reading your articles and salute you Sir.
Pingback: Data is a Property…concept gets support from TRAI – Privacy Knowledge Center