(…Continued)

As a further refinement of the DGPSI system for Sectoral compliance, Naavi/FDPPI presents for public debate, the DGPSI-Bank Branch framework. This follows the foundation principle of DGPSI namely “Distributed Responsibility” in DPDPA Compliance.
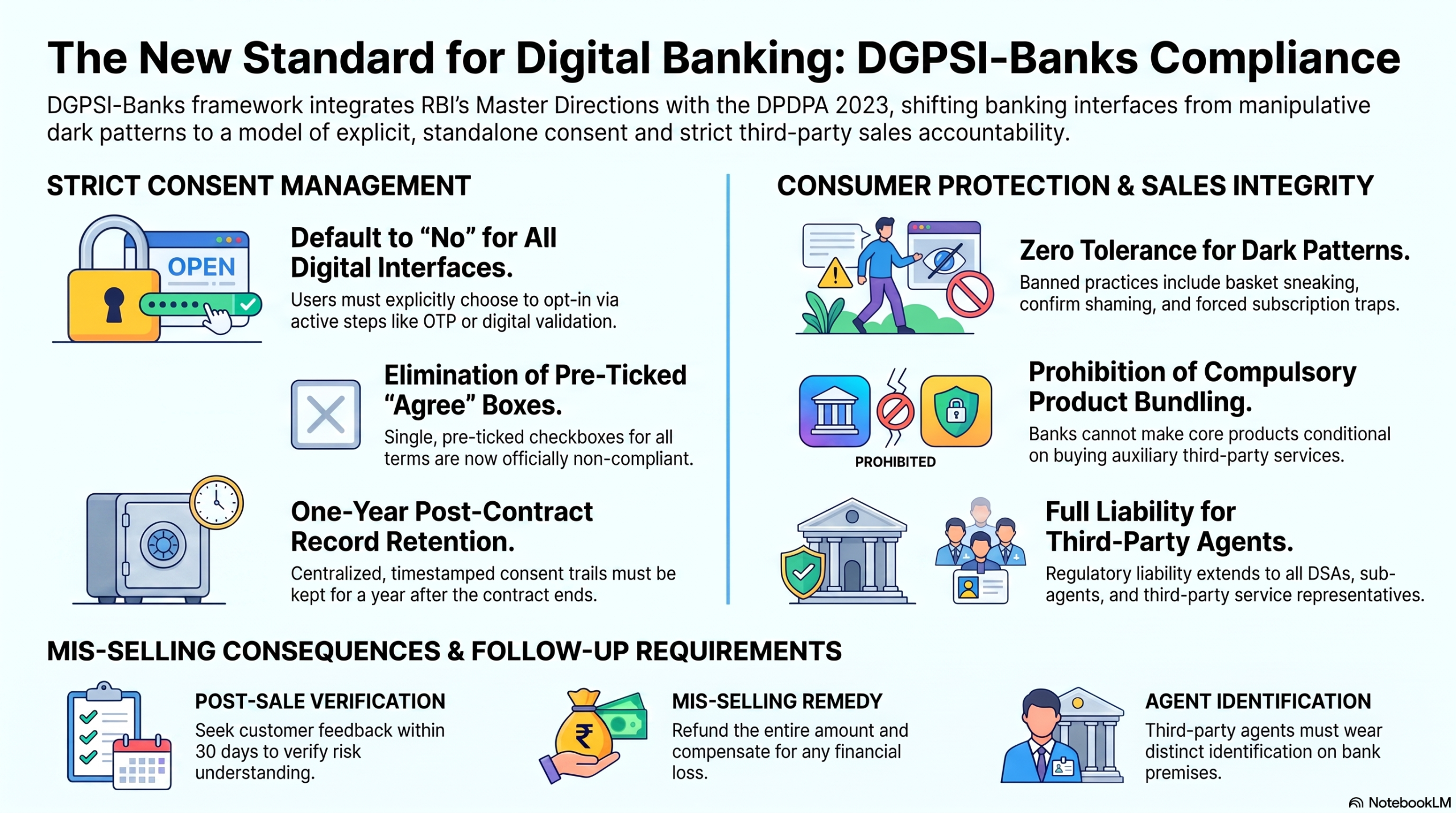
DGPSI-Bank Branch is a comprehensive framework tailored for Indian bank branches. It acknowledges that compliance starts at the ground level and provides actionable guidance, taking into account the unique operating environment of a bank branch.
Key Features:
Branch as a Compliance Unit:
The framework recognizes each bank branch as an independent unit responsible for personal data processing within its operations.
Empowered Branch Manager:
It designates the Branch Manager as the dedicated Data Protection Officer (DPO) at the branch level, equipping them with the necessary tools and guidance.
Harmonized Compliance:
The framework integrates DPDPA requirements with existing regulatory mandates, including RBI Master Directions and Head Office (HO) directives, ensuring seamless compliance.
Practical Checklists and Toolkits:
It will provide user-friendly checklists, assessment tools, and practical guidance on data mapping, consent management, data security measures, and breach response.
Step-by-Step Implementation Guide:
DGPSI-Bank Branch offers a structured, step-by-step approach to implementing DPDPA compliance within the branch, covering:
Data Discovery and Mapping:
Identifying and classifying personal data processed within the branch.
Consent Management:
Implementing robust consent mechanisms and ensuring lawful processing.
Data Security & Retention:
Enforcing appropriate security controls and adhering to data retention policies.
Individual Rights Handling:
Managing and responding to requests from individuals regarding their data.
Transparency & Notice:
Providing clear and concise information to individuals about data processing.
Data Breach Notification
Providing appropriate data breach identification and notification to the Central DPO
Vendor Management:
Evaluating and monitoring third-party vendors for DPDPA compliance.
Training and Awareness:
Sensitizing branch staff about DPDPA principles and best practices.
Why DGPSI-Bank Branch?
Localized and Relevant:
The framework addresses the specific nuances and challenges of bank branch operations in India.
Reduced Compliance Burden:
By providing structured guidance and ready-to-use tools, it minimizes the complexity and effort required for DPDPA compliance.
Enhanced Data Governance:
DGPSI-Bank Branch promotes better data governance practices within the branch, strengthening data security and reducing data privacy risks.
Increased Trust and Confidence:
Proactive DPDPA compliance builds trust and confidence among customers, enhancing the bank’s reputation.
Avoidance of Penalties:
Adherence to the framework helps branches avoid substantial penalties and legal repercussions associated with non-compliance.
Target Audience:
Branch Managers:
The designated DPOs for their branches, responsible for leading compliance efforts.
Operations Managers:
Key personnel involved in data processing within the branch.
Compliance Officers:
Staff responsible for overall compliance within the bank.
Head Office Executives:
Those responsible for overseeing DPDPA implementation across the bank’s network.
Getting Started:
Review the DGPSI-Bank Branch Framework Document:
Gain a thorough understanding of the principles and requirements. Watch out for in-house training programs conducted by FDPPI for Banks on request.
Assign a Branch DPO:
Appoint the Branch Manager as the dedicated DPO for the branch.
Conduct a Data Audit:
Map the flow of personal data within the branch using the provided templates.
Implement Step-by-Step Guidance:
Follow the implementation guide to put in place the necessary compliance measures.
Utilize the Toolkits:
Leverage the practical checklists and tools for ongoing compliance monitoring and assessment.
By adopting DGPSI-Bank Branch, Indian bank branches can confidently navigate the landscape of DPDPA compliance, creating a secure and transparent data ecosystem that protects customer privacy and enhances trust.
(Naavi would be available for conducting training programs to explain this concept to HO level DPOs of Banks)
…Watch out for more..
Naavi














")


