One of the distinguishing features of the Digital Personal Data Protection Act, 2023 (DPDPA) is that it places accountability at the centre of personal data governance. The law identifies the Data Fiduciary as the entity that determines the purpose and means of processing personal data and makes that entity responsible for complying with the obligations prescribed under the Act.
In legal terms, the position appears straightforward. A bank is a corporate entity and therefore the Bank is the Data Fiduciary. Its branches are merely operational units and not separate legal persons. Consequently, the branches are not independently recognized as Data Fiduciaries under DPDPA.
However, legal definitions do not always reflect operational realities.
The Reality of Banking Operations
Modern banks operate on sophisticated Core Banking Systems (CBS), giving the impression that all customer information is centrally managed. While this is technologically true, it does not mean that personal data is processed only at the Head Office.
In the Banking practice before the advent of “Anywhere Banking”, a Customer was a customer of a Branch. This concept has now undergone a change and Banks recognize that a Customer is a Customer of the Bank with a “Parent Branch” being recognized for the purpose of documentation.
This change brought by the Digital Banking system is not however ideal for the compliance of DPDPA since the collection of personal data often originates at the branch level and then gets onboarded on to the enterprise servers. Consent Management therefore happens at the Branch level. However the KYC may be managed by an organization which has a contract signed at the HO level and not at the branch level.
In cases where Branches use the services of centrally appointed service providers for KYC etc, the status of the Head office and its vendor needs to be defined along with that of the branch as either Data Fiduciary, Joint Data Fiduciary or Data Processor.
Customer grievances are handled at branches as well as through the website.
Loans are processed through branch-level officers and by the models governed by the Central office while loan assets are often managed physically at the Branch level. Documents are collected, verified, digitized and stored through branch operations.
Hence, even where centralized databases exist, the operational handling of personal data remains highly decentralized.
For a customer, the Branch Manager is the face of the Bank. It is the branch that decides how the customer is onboarded, how documentation is verified, how service requests are processed and, in many cases, how customer data is shared with third parties for legitimate banking operations.
The Branch, therefore, exercises significant operational control over personal data.
Centralized Systems, Decentralized Processing
This distinction between centralized storage and decentralized processing is becoming even more complicated because many branches independently use:
-
- AI-assisted customer service tools.
- Document verification software.
- OCR-based KYC applications.
- Loan scoring models.
- Fraud detection systems.
- Analytics platforms.
- Cloud-based business applications.
Branches also interact with numerous third-party service providers such as:
-
- Recovery agencies.
- Valuation agencies.
- Legal firms.
- Marketing agencies.
- Document digitization vendors.
- Collection agencies.
- Technology support vendors.
Each of these relationships may involve processing of personal data.
Although corporate policies may require approval from the Head Office, operational decisions are frequently taken at the branch level, creating a situation where privacy risks arise far away from the office of the Bank’s Data Protection Officer (DPO).
A Governance Gap
This creates an interesting governance challenge for DPDPA Compliance.
Legally, accountability rests with the Bank. Operationally, responsibility is distributed across hundreds or even thousands of branches.
Traditional compliance models tend to assume that privacy governance is centralized. In practice, however, DPDPA compliance succeeds or fails at the operational level.
If a branch employee collects excessive information…
If customer consent is not properly recorded…
If a local vendor mishandles customer information…
If an AI tool is deployed without adequate assessment…
…the resulting non-compliance affects the Bank as a whole.
The law may hold the Bank accountable, but the operational failure occurs at the branch.
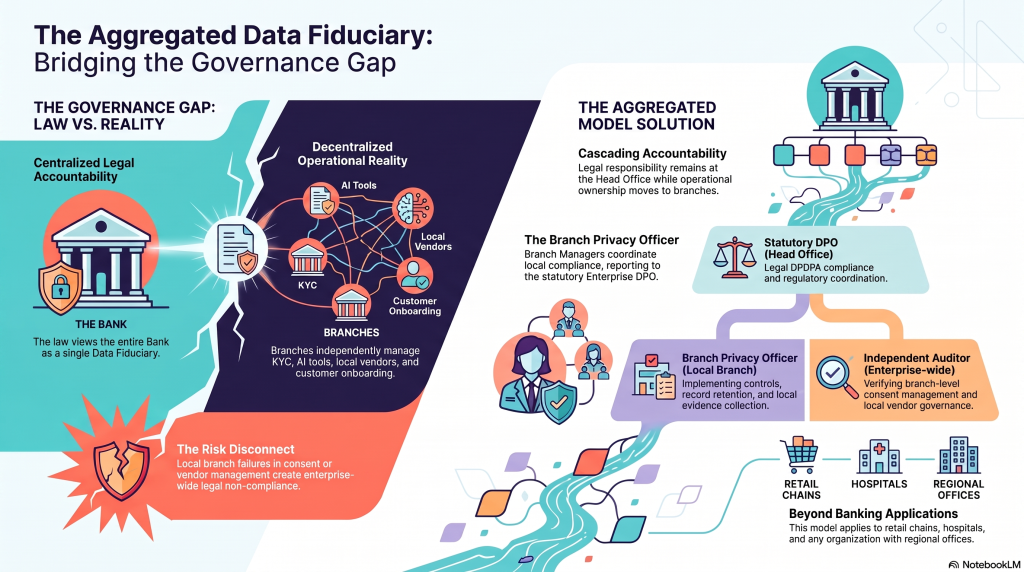
The Concept of an Aggregated Data Fiduciary
To bridge this governance gap, DGPSI-Bank proposes the concept of Bank as an “Aggregated Data Fiduciary” while the branches are “Operational Data Fiduciaries.”
Kindly note that this is a Governance approach and does not legally redefine the concept of Data Fiduciary or a Significant Data Fiduciary. Given the sensitivity of the financial information however, both the Bank and the Branch are to be considered as “Significant Data Fiduciaries”.
Under this model:
-
- The Bank remains the sole legal Data Fiduciary under DPDPA.
- Every branch functions as an Operational Data Fiduciary for governance purposes.
- Accountability is cascaded to the level where processing decisions are actually implemented.
- Enterprise-wide legal responsibility remains centralized.
A company has one Board of Directors, yet each factory, plant, regional office and branch has managers responsible for operational compliance.
Similarly, DPDPA accountability should flow from the Board to the branch.
The Role of the Branch Manager
For most customers, the Branch Manager effectively represents the Bank.
Accordingly, the Branch Manager should ordinarily function as the Branch Privacy Officer or Branch Data Protection Coordinator, unless another officer is specifically designated for this purpose.
This should not be confused with the statutory DPO appointed by the Bank.
The enterprise DPO continues to discharge the legal responsibilities prescribed under DPDPA, while the Branch Privacy Officer becomes responsible for implementing privacy controls, maintaining records, ensuring evidence of compliance and coordinating with the central privacy office.
This creates a practical governance hierarchy without altering the statutory framework.
Implications for Independent Data Auditors
The concept of an Aggregated Data Fiduciary also has important implications for Independent Data Auditors.
An audit limited to Head Office policies is unlikely to provide meaningful assurance regarding actual compliance.
Auditors should evaluate:
-
- Branch-level consent management.
- Local vendor governance.
- AI deployment practices.
- Record retention.
- Employee awareness.
- Incident reporting.
- Privacy governance.
- Evidence supporting compliance.
Only then can an Independent Data Auditor provide credible assurance regarding DPDPA compliance.
Beyond Banking
Although the banking industry provides a compelling illustration, the concept has much wider application.
Insurance companies.
Large hospital networks.
Retail chains.
Telecommunication operators.
Educational institutions with multiple campuses.
Government departments with regional offices.
Public Sector Undertakings.
Franchise-based business models.
In all these cases, the legal Data Fiduciary is a single entity, while operational processing is widely distributed.
The Aggregated Data Fiduciary model offers a structured mechanism for distributing operational responsibility without diluting legal accountability.
A Natural Evolution of DPDPA Governance
Earlier, we had proposed the concept of a Super Data Fiduciary to describe organizations that exercise overarching governance over multiple independently operating entities, particularly in sectors such as healthcare.
The concept of an Aggregated Data Fiduciary addresses a different challenge.
It recognizes that within a single legal entity, operational responsibility may itself be distributed across numerous business units that process personal data on a daily basis.
As organizations increasingly adopt AI, cloud services and decentralized digital operations, this governance model becomes even more relevant.
DPDPA establishes legal accountability. Organizations must now develop governance structures that make that accountability operational.
The concept of the Aggregated Data Fiduciary is one such framework. It enables organizations to combine centralized legal responsibility with decentralized operational ownership, thereby strengthening governance, improving auditability and making DPDPA compliance more effective.
It is hoped that regulators, compliance professionals, auditors and industry bodies will examine this concept and contribute to its refinement as India’s data protection jurisprudence continues to evolve.
Open for public Deabte.
Naavi





")


