“Anonymization” takes personal data out of the purview of most data protection regulations. Hence it is one of the objectives of data protection compliance managers to mitigate the data protection risks by pushing part of the “Protected Data” out of the “Protection Zone” by “Anonymizing it.
In the Indian PDPA, the Data Protection Authority is eventually expected to provide an explanation of when a “Personal Data” is deemed to be “Anonymized”.
For an organization, “Data” to be Governed includes “Personal Data” as well as “Anonymized Data”. Just because a certain data element is anonymized, it may not mean that it is no longer an asset that need not be secured. In fact, many organizations may acquire “Identified Personal Data” at a cost and there after spend more to anonymize it. So, Anonymised data may be more valuable as an asset than the identified data from the “Cost of Acquistion” point of view.
However, the need to secure “personal data” because of the regulations and the possibility of a heavy financial penalty in case of failure introduces another element of “Opportunity Cost” to the identified personal data arising out of data breach and/or non compliance of data security regulations.
A Corporate Manager who is interested in “Data Governance” (Data Governance Officer or DGO) is concerned both with the “Cost of Acquisition” as well as the “Cost of non compliance”. The “Data Protection Officer” (DPO) on the other hand is interested only in the “Non Compliance Cost”.
“Anonymization” is a process that acts as a gateway between the DGO’s territory and DPO’s territory. The DGO hands over the data as “Identified Personal Data to the DPO for Compliance management. At the same time, he would have retained what is classified as “Anonymized Data”. The anonymized data may go for a separate shop floor for a process of adding value through “Data Analytics”.
If however, the “Anonymization Process” is not good enough, then the organization would be exposed to the re-identification risk. The demand for penalty in that case would come from the supervisory authority to the DPO.
DPO is therefore responsible for the “Adequacy” of the “Anonymization Process”. In fact if a company adopts “Anonymization” as a part of its Data Management policies then the “Anonymization Process” should be subjected to a DPIA (Data Protection Impact Assessment) by the DPO.
Probably these are situations when there would be a conflict between the DGO and the DPO. While the DPO may blame the DGO for imperfect anonymization, DGO may blame the DPO for “Motivated Re-identification” in a downstream process.
Let us leave this conflict to be resolved by the proper structuring of the “Data Governance Framework” which should include the “Data Protection Framework as a subset”.
In the meantime, let us briefly look back on Naavi’s Theory of Data and see whether this theory can recognize the journey of data from “Personal Data” status to “Anonymized Data” status.
In the theory of data, we had included a “Reversible Life Cycle Hypothesis”. This was part of the three hypotheses that made up the theory including the other two hypotheses namely the “Definition hypothesis” and “Additive value hypothesis of ownership” .
The essence of the theory was that “Data is Constructed by technology and Interpreted by Humans”, Data undergoes a lifecycle of birth to adulthood to different stages of maturity and then death, providing ownership to different persons for different value additions”.
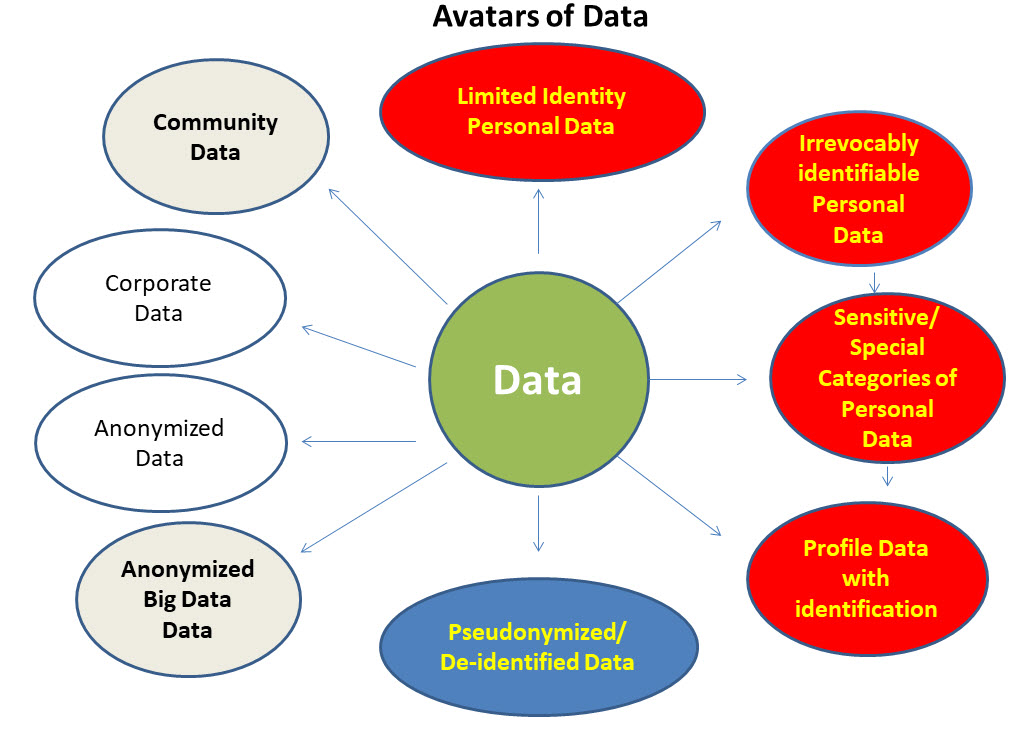
If we try to trace the life cycle of personal data through anonymization we can identify that data goes through different phases of development in which it will assume different avatars as shown in the diagram above.
A Company may normally acquire data in the form of a limited personal data collected in a web form or when a netizen clicks on a web advertisement or visits a website. At this point of time the company may get some limited identity parameters such as the IP address of the person and possibly the name and email address he fills up on a web form. This Limited personal data later may acquire the status of an “Irrevocably identifiable personal data” if some elements of identification such as a PAN number or a Mobile number etc is collected or become a sensitive personal data if the collected data elements include specific data elements.If processed into a profile it may become profile data.
If the company removes the identity parameters and keep it separately, it may become “Pseudonymized data”. If the identity parameters are irrevocably destroyed the data may become “Anonymized Data”. The anonymized data may be aggregated into big data.
In between all these categories, part of the limited identity personal data or identified personal data or anonymized data may be called “Community data” if it contains the data of a group of individuals.
In all the above avatars the “Corporate Data” is a class of its own and may be further classified as IP data, Business Intelligence data, HR data, Finance Data etc.
While the “Data Protection laws” may apply to Personal data, Sensitive personal data and profile data, Cyber Crime laws such as ITA 2000 will apply to all data including personal data. In future, a Data Governance Act of India may also come to apply to “Non Personal Data”, “Aggregated Data”, “Community Data” etc.
The fact that “Data” exists in multiple forms and one can change into other and back is a point which is well captured by the “Reversible life cycle hypothesis of the Theory of Data”. The fact that different laws may apply to it at different stages is also explained by the life cycle hypothesis. The only difference between the human life cycle and the data life cycle is that data life cycle can be reversed in the sense that non personal data can become personal data and later come back to non personal data status. Humans may not be able to do so except when they are mythological characters like …Yayati and Puru.
What the Theory of Data highlights is that any regulation which does not take into consideration that “Data” changes its nature in the ordinary course of its usage and a “Dynamic Data” requires a “Dynamic Regulation” will have problems.
In the human equivalent, we have the issue of a law applicable to juveniles being different from the law applicable to adults. similarly law applicable to unmarried may be different from law applicable to married, law applicable to men can be different from law applicable to women, law applicable to Hindus may be different from law applicable to Muslims and so on.
Just as there is strength in the argument that there should be a “Uniform” law for humans, there should also be an attempt to explore if “One comprehensive law of data” can cover both Personal Data and Non Personal Data.
In view of the important transition of applicable regulations when data crosses the border of anonymization, the management of the anonymization gateway is a critical function of Data Governance.
One debate that has already come up is whether there can be a “Standard of Anonymization”?
If so, how will it be different from de-identification standard which defines certain parameters as “Identity parameters” and if they are not present in a data set, the data set is considered de-identified or otherwise it is identified”.
The “Anonymization standard” cannot be that simple since it should be considered computationally infeasible to re-identify an anonymized data.
“Computational Infeasibility” of re-identification comes from the erasure of the “Meta Data” which needs to be irrevocably removed. We all know that if we create a word document, the details of the author is perhaps known to “Microsoft”. If therefore the document is to be anonymized, we need to check if whatever meta data is associated with the document and wherever it is stored, is permanently destroyed.
“MetaData identifier Destruction” could perhaps be the difference between the “De-identification/Pseudonymization” and “Anonymization” .
In Forensic destruction of data, early DOD standards required data erasure for several times before a data holding device is said to be sanitized. This implies that even when data is forensically erased, a certain number of repetitions are required to ensure that the process cannot be reversed by an intelligent de-sanitization algorithm.
The essence of this “Anonymization” through forensic over writing of data bits is to randomize the overwriting process so that it cannot be reversed.
The standard of anonymization that can be recommended to DPA is therefore not necessarily over writing all bits to be sanitized with a zero bit several times.
It can be different and is aimed at randomizing the binary bit distribution in the data holding device. An example of such a process could be..
a) Overwrite all the bit sets that represent the identification parameters with zero but in a random sequence. (This presupposes that the data set can be divided into identity parameters and other data associated with the identity parameters)
b) Repeat by over writing all the bit sets once again with say 1 again in a random sequence
c) Repeat by spraying zeros and ones randomly on all the data bits in the zone
This process may leave a random distribution of zeros and ones in the selected zone which cannot be reversed. As long as the rest of the data does not contain any identity parameters, the data can be considered as “Anonymized”.
May be technology experts can throw more light on this.
Naavi
Reference:
DOD standard for data erasure







