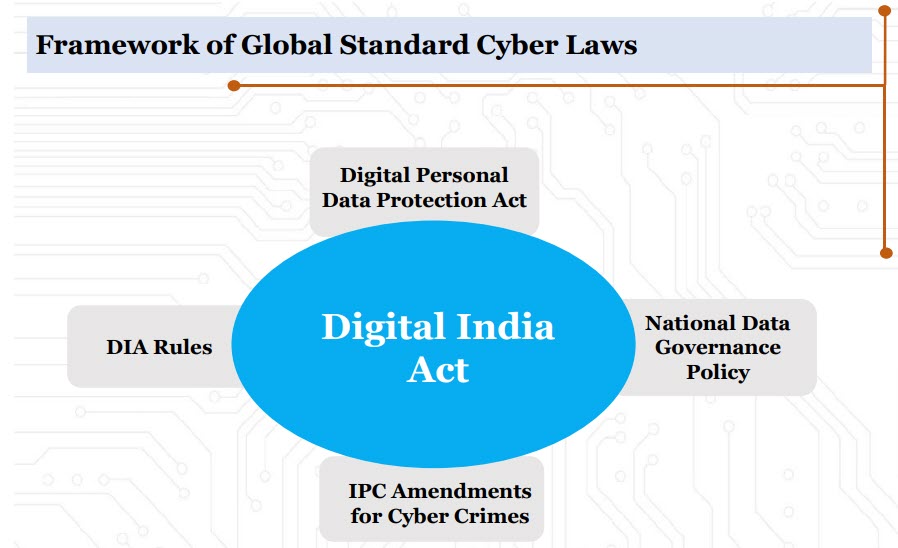
On May 26th, 2022, the MeitY had released the “National Data Governance Framework Policy” for public consultation. Mr Rajeev Chandrashekar has made a reference to this policy while introducing the proposed Digital India Act and stated that this policy would be part of the ensuing Cyber Law eco system of India.
The objective of this policy was to ensure that non-personal data and anonymised data from Government and Private entities are safely accessible by research and innovation eco-system. According to the press release of the Government issued on 27th July 2022 in this regard, the policy was meant to provide an institutional framework for data/datasets/metadata rules, standards, guidelines and protocols for sharing of non personal data sets while ensuring privacy, security and trust.
Now this policy, a draft of which was made public in 2022 (Refer here) becomes integral to the Cyber Law eco system in the country and will have an impact even on DPDPB2022. The objectives of this policy included building a platform where “Data” can be made available for processing by the Big Data industry. It would also impact the AI development systems by contributing data for Machine Learning modelling. (Also refer here for more on the policy)
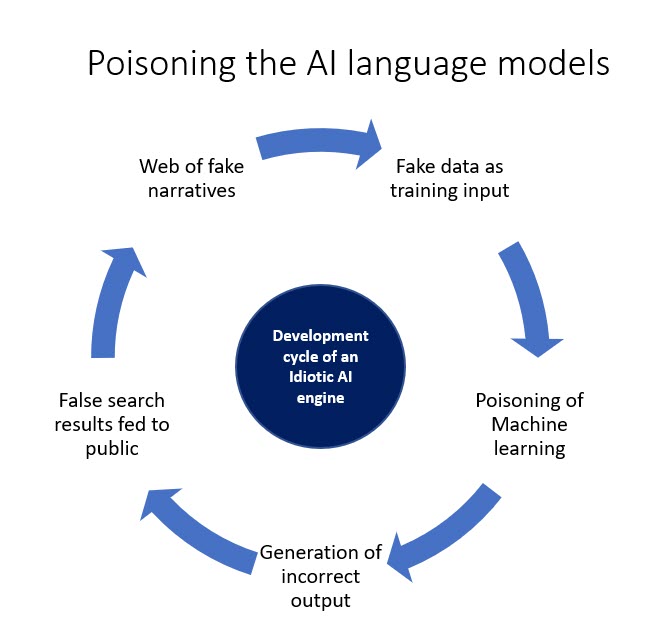
In the context of the penetration of Large Language Models such as the ChatGPT in the ecosystem, the need for unbiased data set for Machine Learning is critical. The public opinion in future would be automatically framed by the large language models which have the capability of making people believe untruth as truth. The models like the new Bing Search Engines built on this “Idiotic but pretending to be Intelligent” language models may rationalize fake narratives on the web if web information becomes the predominant training data set. These models are amenable to “AI Training Data Poisoning” threat which needs to be prevented if we want the integrity of the ChatGPT like models to be preserved.
As an example arising out of the current narratives floating in the internet, it would not be surprising if the language model confidently says that “Indian Democracy is under threat because of Mr Modi while the truth could be that it is under threat because of Rahul Gandhi”. The “Garbage In, Garbage Out model” of training of AI models would come to this conclusion because the fake narrative may be more prolific than the true narrative. This would be true of all social issues since people spread negative information faster than true information and the media looks at this as an opportunity to increase their TRP. This would lead to the development of a distorted view of the society.
At any point of time web will contain more negative and false information than truthful and positive information. This will creep into the language model dependent search engines and corrupt the society irretrievably over a period.
I reproduce here the first paragraph of an article (Is it a George Soros sponsored article?) “intelligencesquared.com” . The article is reported as an introduction to a debate with Siddarth Varadarajan , Founding editor of The Wire and Bobby Ghosh, a member of the Bloomberg’s editorial board participating.
Quote
India may be the world’s largest democracy, but under Prime Minister Narendra Modi the country is sliding inexorably towards autocracy. In his six years in office, Modi has presided over an increase in arrests, intimidation and the alleged torture of lawyers, journalists and activists who speak out against him. His Hindu nationalist government has amended its citizenship laws to favour Hindus over Muslims and has pledged to create a national register of citizens, prompting concern that millions of Muslims with inadequate paperwork will be unable to qualify for citizenship. Modi doesn’t like to hear dissent: while in power he has not held a single press conference or given any unscripted interviews. Several international organisations have now marked India as only ‘partly free’ or as a ‘flawed democracy’. This great, vibrant, argumentative country with a proud history of debate has never seen anything like this prime minister: Narendra Modi is the most serious threat Indian democracy has ever faced.
Unquote
The second paragraph provides a brief mention of the opposing view and then goes onto introduce an even in which two speakers will speak. This is a clever presentation of data which the search engines and AI algorithms will pick as the narrative represented by the heading and the first paragraph.
Any AI model to which this paragraph goes as an input would definitely create a biased output. As the biased output percolates into the public mind through search engines such as the Bing search, the public will slowly start believing the fake narrative.
The new DIA flags the need for preventing fake social media narrative as one of its objectives in creating an “Open but Safe” Internet. At the same time the tendency of the law makers is to exempt “Online Search Engines” from most of the regulatory controls in the belief that the search engine output is unbiased. This presumption is however incorrect in the era of ChatGPT since “Fake planted articles on the web” will reinforce the learning of the Chat GPT like platforms and increase the Bias in each cycle of learning.
Hence filtering the data set used for machine learning is necessary to avoid bias creeping in to the AI model in its decision making.
Regulation of AI is also part of the DIA objective and “Prevention of Bias” is declared as one of the most important ethical challenges.
The DIA therefore needs to ensure that a reliable data set needs to be created out of unbiased basic data. This is an important regulatory aspect required to maintain the integrity of the search engines and large language models.
We have already suggested that AI algorithms need to be held accountable to the creators through a system of labelling, licensing and registration. The use of reliable data set for the training process is one of the parameters for accreditation of AI algorithms to be registered by the AI regulatory authority.
Meity had released certain reports on AI (Refer here). Out of the four reports published, Report of Committee D which has addressed the ethical issues of AI has suggested the need for measures to avoid bias in AI. Now some of these suggestions have to be part of the DIA.
We draw the attention of the Meity and request for considering measures to prevent “Poisoning of AI Training.”.
Naavi




")


