Yesterday, I made an announcement that I will be working on a “Theory of Data”. I consider www.naavi.org as a global publication platform. All my work most of which are products of my own research have been published here. Hence the objective of codifying a “Theory of Data” is also being elaborated here.
Naavi
Why this exercise?
“Data” has become a topic of wide interest in our world from Mark Zuckerberg to Mr Narendra Modi, from Justice Srikrishna to the Mr Mukesh Ambani . Everybody is speaking about Data.
But different people speak of Data in different perspectives. When Mr Modi says “Data is cheap” in India and therefore international business should find it attractive to do business in India using Data as a raw material. Somewhere else Data Protection professionals say, “Data” is “Gold” and very valuable. Industry 4.0 says “Data is the New Oil” and can be harnessed for prosperity.
In one previous occasion, Naavi has likened the “Samudra Manthana” story in Indian Puranas to describe how Data can be churned with the right tools to extract useful outputs as long as there is a “Visha Kanta” to gulp the poison that may come out and a “Mohini” to ensure that the “Amrutha or Nector” does not fall into wrong hands.
The Data Scientists and the Big Data Industry are concerned that with so much of interest being shown on what is their raw material, the day is not far off when their business will become a play ground for people of every kind. This may actually land the industry in trouble sooner or later since different people come with different perspectives and unless a common understanding emerges, industry cannot have a turbulence free eco system to operate in.
Data Protection Vs Governance
For some, “Data” is the key to Privacy Protection. For others “Data” is the Key to enrichment. For some others “Data” is like the air we breath, access to which should be a fundamental right. For some “Data” is an asset which can be converted into Cash either lawfully or unlawfully through “Data harnessing” or “Data Exploitation” or “Data Laundering”
Between the different perspectives that exist about “Data”, the law makers are trying to make laws to regulate the Life Cycle of Data such as collection, use, storage, disclosure and destruction of data. These regulations are to be implemented by organizations and are expected to be followed by the entire global population at all times. Failure to be compliant with the laws results in heavy penalties for the business managers often ending them with the prospect of imprisonment.
Those who want to govern business in a lawful manner are exploring the ways of “Data Governance” for better productivity while the regulators are watching every one of their steps to ensure that they remain within the boundaries of law.
Data Protection professionals are developing a framework for protection while Data Governance Professionals are going beyond Data Protection Framework to develop a Data Governance Framework.
Already, we see conflicts emerging with the multitude of Data Protection Laws that make the life of a Data Manager miserable. While Data moves across geographical boundaries freely, when we see that this data consists of Personal Data of Indians, EU Citizens, Californians, Canadians, Australians etc., the Data Governance official is immediately alerted to the fact that each of these data types are subject to different regulations and the Governance model needs to implement them in such a manner that there is no contravention of any of these laws.
These are conflicts arising out of overlapping regulations and we need a solution to overcome the challenges. Naavi has suggested a technical solution within the framework of a Personal Data Protection Standard of India (PDPSI) to address this issue.
But as we go along, there will be conflicts arising out of Data Protection Professionals taking a stand different from the Data Governance Professionals when implementing certain operational decisions of business. This conflict is dangerous since it is internal to an organization, will expose all the behavioural challenges that confront all Man Managers.
If this internal conflict is not handled with finesse, an organization can simply collapse not because its business environment is negative, but because the internal management teams donot see eye to eye because each of them think that they are correct and the other person is wrong.
It is this concern of the problem of the future generation of corporate managers that has prompted me to start work on developing a “Theory of Data” that tries to develop an understanding of Data that all types of professionals whether they are Lawyers or Computer Engineers or Data Analysts or Corporate Managers appreciate with mutual respect and empathy.
This Theory of Data should be consistent with the present and future regulations related to data. However since some regulations are already in place, it is possible that they may not be in sync with this theory. However it is expected that “Jurisprudence” will enable syncing of the present regulations with this theory while new regulations may adopt the concepts propounded in this theory during the construction of the regulation itself.
This “Naavi’s Theory of Data” does not explore the “Technical aspects” but addresses the “Legal”, Behavioural Science” and “Management” aspects of how “Data” comes into existence and lives through its life until its death. If it is necessary to distinguish this theory with the existing theories, then it may be necessary to identify this theory as “Naavi’s theory of Data” or “LBM Theory of Data”. For the rest of our discussion here, we shall however refer to this as simply the “Theory of Data”.
Theory and Hypothesis
The hall mark of a “Theory” is supposed to be establishment of a principle through experimentation and testing. It may start with a hypothesis which is a statement of what a situation is as per an educated guess. Then through various experimentation, the hypothesis is either proved or disproved or further refined until it becomes the theory.
Naavi’s Theory of Data will also adopt a similar approach of first pronouncing some hypothesis and then subjecting it to observations that either support it or refine it.
If other readers have a hypothesis of their own, they are free to submit it to me and I will try to incorporate a discussion on such hypothesis also as part of the development of this theory.
This is therefore a journey which we are starting now.
Naavi
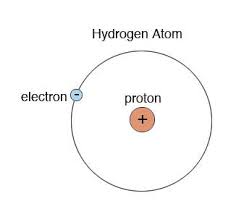 In comparison, a Helium atom is heavier with two protons and two neutrons in the nucleus with two electrons revolving around the nucleus.
In comparison, a Helium atom is heavier with two protons and two neutrons in the nucleus with two electrons revolving around the nucleus.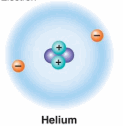 Hydrogen and oxygen combine together they may together form a liquid called water. Some of the molecules may be so tightly bound that they even become solids.
Hydrogen and oxygen combine together they may together form a liquid called water. Some of the molecules may be so tightly bound that they even become solids.




