
When an AI algorithm is trained, there is a dilemma that we need to address. Normally a Computer is expected to have 100% accurate memory of data that has been stored inside. Human brain however functions with its own infirmities one of which is a tendency to have uncertain memory. The normal human memory has a “Fading” nature where memory fades with time. There are however exceptions where some memories particularly with a high emotional significance tend to remain fresher than others. Similarly perceptions with multiple senses tend to remain in memory longer.
In order to ensure that an AI algorithm is efficient, the output has to be similar to human behaviour and hence one school of thought is that this trait of “Memory Fading” needs to be factored into the behaviour of an Algorithm. At the same time, many may argue why make the system which is naturally a memory efficient system to degrade itself.
In areas where humans build “Muscle Memory” over years of training, AI led Robots can be programmed instantly and it would be worthwhile to do so. if the robots are required to remember the instructions permanently. However, in some applications where there is a need for the output to be more human, it would be better if the output is tempered with the time value of data so that older data has less weightage than recent data. One such situation is “Valuation of Personal Data”.
In suggesting a “Personal Data Valuation System” under Data Valuation Standard of India (DVSI) we were struggling to accommodate the formula for valuing data as it ages. Now AI may be able to find a solution to this complex problem of “Personal Data Valuation”.
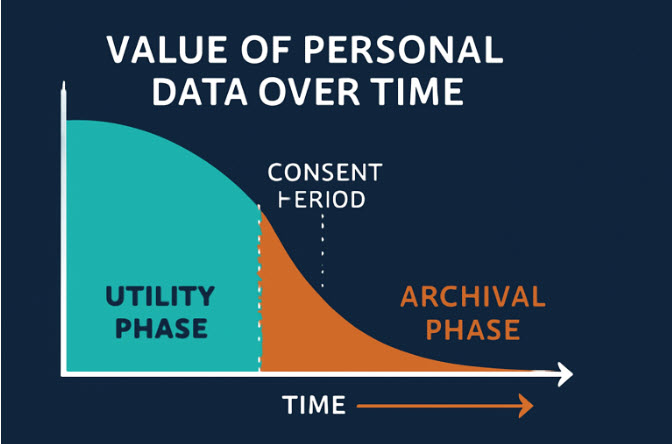
In personal data domain, the value depends on its utility and hence if the consent of the data principal is restricted in time, it should automatically reflect in the value of the data. The data may have to follow a linear degradation and a wipe out after the end of the consent period. If the data is archived under legitimate use, the value may drop from the “Utility phase” to the “Archival Phase”.
Currently Machine Learning specialists speak of different techniques such as the following to incorporate the differential weightage of data value for learning process.
1. Time Decay Weighting
-
-
Exponential or Linear Decay: Assigns weights to samples based on how recently they were recorded, with more recent data points given higher weights.
-
-
-
This approach is commonly used in recommender systems, time series models, and search algorithms to ensure the model adapts quickly to recent trends
-
2. Decay-Weighted Loss Functions
-
-
The loss function during training incorporates weights for each data instance based on its age. Recent samples contribute more to the loss, guiding the model to learn primarily from the most up-to-date information
-
-
-
Example: Adaptive Decay-Weighted ARMA, a method for time series forecasting, modifies the loss function with a decay weighting function so that the influence of observations decays with age
-
3. Sample Weighting or Instance Weighting
-
-
Most machine learning libraries allow you to specify sample weights when training models. By assigning larger weights to recent data, algorithms like gradient boosting, neural networks, or linear regression can be skewed to prioritize fresh inputs
-
-
-
This approach is algorithm-agnostic and is especially practical for datasets where age can be explicitly measured or timestamped.
-
4. Age-of-Information (AoI) Weighting in Federated & Distributed Learning
-
-
In distributed or federated learning, gradients or updates from devices with fresher data are weighted more heavily. One example: age-weighted FedSGD uses a weighting factor reflecting the recency of data (Age-of-Information), which helps achieve faster convergence and improved performance in non-IID (non-identically distributed) scenarios
-
-
-
The technique calculates and applies an “age” metric for each device/data shard, promoting those that just contributed fresh samples.
-
5. Rolling Windows & Sliding Windows
-
-
Instead of weighting, some systems simply drop older data altogether and retrain or update the model using only data from a recent rolling window. This method indirectly links the model’s knowledge only to recent history.
-
When it comes to valuation of utility of personal data, the impact of data protection laws which link the utility to the “Consent” of the data principal need to be incorporated into the valuation module. Hence Machine Learning specialists need to discover newer algorithms which ingest a basic utility value moderated by aging with a link to the consent period. It should also incorporate a lower utility level during the legitimate use period post consent period when the personal data moves from the active storage to archival or is anonymised and moved to research data store.
A similar consideration of valuation of personal data will also arise when the Regulatory Authorities determine the level of penalty for data loss as was recently reported in South Korea where penalties were imposed on some educational institutions for loss of data which was 20-40 years old. Whether the penalty was reasonable in this context or not remains a debatable issue. When the Indian DPB is confronted with similar issues there is a need to develop an AI algorithm that would determine a “Reasonable Penalty” for the failure of “Reasonable Security”.
AI Chair of FDPPI invites AI researchers to develop an appropriate model for making the penalty decision less subjective by recommending a proper system that evaluates what is the value of data lost in a data breach situation.
Naavi




")


