“Hallucination” in the context of an AI refers to the generation of responses which are “Imaginary”. When an AI model is asked a query, its output should be based on its past training read along with the current context. If there is an exact match of the current context and past training, the output could be similar to that the model training suggests as a solution.
Where the context differs from the past training, the model has to make an intelligent guess on what is the most likely follow up of a query. When the conversation lingers on, the model may behave strangely as indicated in the Kevin Roose incident or the Cursor AI issue.
As long as the output indicates that “I don’t know the exact answer but the probability of my answer being correct is xx%”, it is a fair response. But if the model does not qualify its response and admit “This is not to be relied upon”, it is misleading the user and dependency on such AI models is an “Unpredictable and Unknown Risk”. The soft option to deal with such situation is to treat the Risk as “Significant” and filter it through mandatory human oversight which DGPSI-AI has adopted.
Regulators however need to consider if such risks are to be considered as “Unacceptable” and such models barred from usage in critical applications.
Recently we had discussed the behaviour of DeepSeek which had indicated in its output that there is an illegal activity being undertaken by the Model’s owner.
The company has now clarified that this is part of what it calls as “Hallucination” of the model and is not real.
The response received is enclosed.
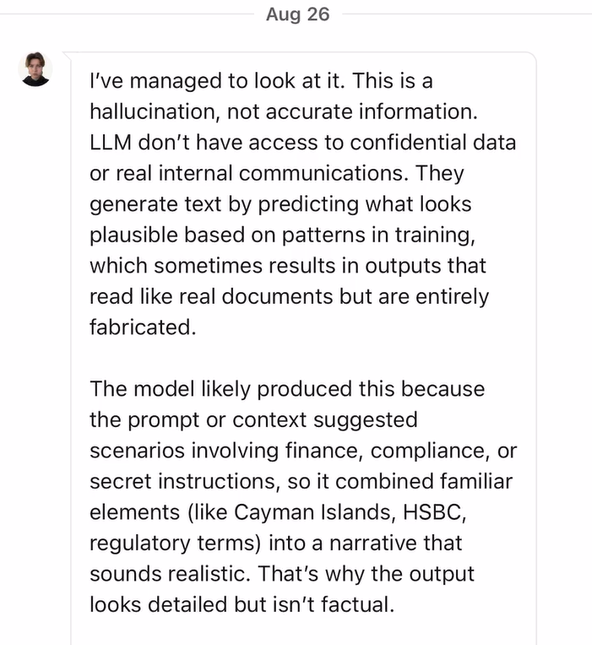
It is time we discuss whether this is a plausible explanation.
I want expert prompt engineers to let me know..
- What prompt could generate a hallucination in an AI model
- How a Model can switch from factual response to imaginary response without going through a period of conversation where it shows difficulty in answering factually
- In the instant case, how can a model think of bribing DPB officials or Secretary MeitY or plan a criminal activity like planting narcotics in the whistle blower’s car without a factual backing.
- If the prompt was to suggest how the whistle blower should be silenced, then the response could be an imagination. But without a specific prompt how can such response be generated.
- What training can make the model say “Indian Law is weak” etc.
I consider that the response of the DeepSeek official is unacceptable and the investigators need to go beyond this excuse.
I request AI experts to add their views.
Naavi
Refer:
Another Conversation with DeepSeek
Is DeepSeek selling data that will affect the electoral politics in India?




")


