[PDPSI is the Personal Data Protection Standard of India as issued by Cyber Law College, the academic arm of Naavi.org. The objective of the standard is to make available a open source guideline to Indian Companies to comply with Privacy and Data Protection requirements that meet the standards of BS10012, GDPR as well as the Indian laws such as ITA 2000/8 and the proposed PDPA 2018.]
This is in continuation of our previous article, “Data Classification is the first and most important element of PDPSI”in which we had highlighted that “Data Classification” is an important step in the compliance. Before even we determine the “Risks” and initiate “Privacy By Design” and “Information Security Practices”, it is necessary to understand what type of data is in the hands of a company and where it comes in or generated, where it is used, where it is stored and transmitted out.
In our previous article we had indicated 16 types of data classification within the Individually identified data. It is reiterated below for reference.
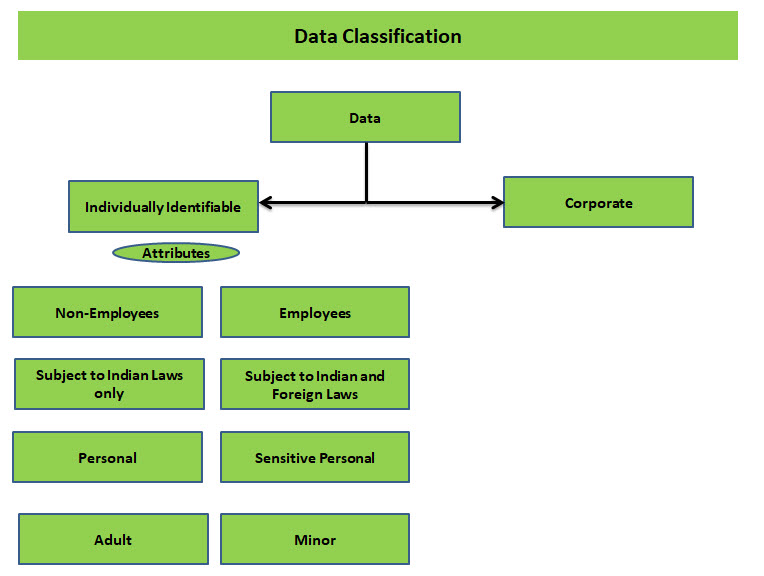
What this chart indicates is that a company should first be able to understand that PDPSI (as well as GDPR or PDPA 2018) applies only to personal information and not to corporate information however important it is.
Protection of all data is the job of the Information Security/Compliance Officer of the Company. Protection of Personal Data is a subset of this larger requirement.
The reason why there appears to be more importance given to compliance of Personal Information instead of all the information is that when there is a non compliance issue related to Personal Information, authorities such as the GDPR or DPA can come in with imposition of penalties for non compliance.
On the other hand any non compliance issues related to non personal data is a “Best Practice” issue and gets escalated only when there is a data breach which qualifies to be called a Cyber Crime and there are victims who invoke law for claiming compensation.
Hence compliance managers and the management are more worried about compliance of “Personal Data Protection” laws rather than “All Data protection” laws though the former should be a sub-set of the latter.
Coming back to the Data Classification exercise, PDPSI has recognized the need to identify 16 types of Individually identifiable data since the compliance requirements can vary for each of these 16 types.
Data is always a “Package” and consists of multiple elements. For Example, Name is personal data and in most cases it is the lead personal data because humans recognize the name. Name often comes with additional associated information such as the E Mail address, the Phone number, the employee ID, residential address, age etc. It may also include the “Meta Data” associated with the transactions of the data subject.
For the purpose of compliance, it is necessary to aggregate all associate data of one person into one “Personal Data Package”. This Personal Data Package is not static and it grows as more and more information flows in to the organization and is associated with the same individual data package recognized by the “Lead personal data element” (LPDE).
It is open to an organization to allocate a customer ID or Employee ID etc to the name of a person and thereafter consider the number as the “LPDE”. It is also open to use a “Pseudonymization key” if required. It is like opening a “Ticket”. All subsequent references to the same individual has to be added to this “Identity Ticket”.
Once a Data Package with a “Designation of the LPDE” is issued a “Data Package Identity” (DPI), the DPI becomes the reference data reference for further usage.
This DPI needs to be allocated different attributes as indicated to define what data protection law would be relevant.
We have identified four levels under which the attributes are being associated.
Level 1: Employee or Non Employee
Level 2: Subject only to Indian laws or to other foreign laws also
Level 3: Personal or Sensitive personal
Level 4: Adult or Minor
The first categorization of Employee and Non Employee is suggested because Employee personal data is subject to employment contracts and may provide the organization with more flexibility than non employee personal data.
The second level of attribute is required because the data subject may be a citizen of one country, resident of another country and the data processing may involve profiling of activities in different countries. Similarly the data may be health data subject to US laws such as HIPAA or Financial data subject to some other law of another country. It is better to identify the scope of compliance by associating which set of laws need to be kept under consideration for securing the subject DPI.
Then comes the distinction of personal and sensitive personal data, since laws my be different even within one statute.
The fourth level attribute is because law may also be different if the data subject is an adult or he is a minor.
Hence we need to identify 16 types of personal data and map the compliance requirements for each of these different types. If we include the first level of “Individually identifiable” and “Corporate” as the Level Zer0, we will occupy a total of 5 bits that are required to identify a data package. If the “Psudonymous state” is also added as an attribute, it would consume the sixth bit in the packet. This leaves another 2 bits in a byte to define the Data Package references. It can be extended to a 16 bit ID space if more attributes need to be added. To avoid the Y2k type problem, we may start with an allocation of 16/32 bit space straight away and keep excess bits vacant so that a “Data Package” will have a distinct identity even as it grows. This should help in implementing “Data Portability” and “Data Erasure” when required.
The PDPSI presents the set of controls required to manage the compliance under PDPA 2018 (presently ITA 2018 until the new law is enacted) and additional controls in the form of annexures depending on whether other laws become relevant. For example one annexure may indicate GDPR requirements for personal data of an Indian Citizen whose activities are monitored by a EU Company. Or that of a EU Citizen who may be profiled for his activities in India. Similarly different annexures may be there for HIPAA compliance, GLBA compliance, CCPA compliance, etc.
We will initially focus on compliance of Indian data protection laws as envisaged under PDPA 2018 and then develop other annexures one by one.
We are aware that PDPA 2018 is only a draft bill now and will have to be re-introduced and passed. But the principles of data protection and therefore the standards will not change even if PDPA 2018 becomes PDPA 2019. Further when the Indian DPA comes into existence, we need to present it with some industry led proposal as a standard so that it can focus only on modifications as may be required.
We hope that PDPSI would become the base standard from which modified versions can be developed by the DPA. We feel that this will at least make the work of DPA simpler and quicker.
(Comments are welcome)
Naavi




")



Pingback: India to be the Hub of International Personal Data Processing.. Objective of PDPSI | Naavi.org
Pingback: Drawing Borders for the Borderless Cyber Space | Naavi.org
Pingback: Earlier Articles | PDPSI