(This is a continuation of the earlier article)
The Government of India has constituted a committee to deliberate on “Data Governance Framework”.
The notification of the committee has defined the “Terms of Reference” as
- To Study various issues relating to Non-Personal Data
- To Make specific suggestions for consideration of the Central Government on regulation of Non Personal Data
Accordingly, what the Government is looking at is a suggestion on “Regulation of Non Personal Data”.
The next question that arises is what is “Non Personal Data” and what are the “Issues relating to Non Personal Data”?
If we look at the preamble to the formation of the committee, there is a reference to SriKrishna Committee recommendations and its reference to ” Aggregation of Personal Data” and the “Generation of Community data through aggregation of individual data”.
The Title of the notification, the preamble and the terms of reference does not seem to converge on the same thought and hence the committee will have to start by first clarifying what it proposes to do.
A general meaning of “Data Governance Framework” (DGF) would be a standard methodology by which data can be managed in an organization from its generation to disposal.
The elements of such a DGF would cover the process of collection, processing, storage, transmission, security, exploitation etc.
Today we are managing data by Classifying it either as Corporate Data or Personal Data. Before the advent of Data Protection regulations, the emphasis was mainly on “Protection of all Data” that an enterprise controls.
The treatment of data was basically like an “Asset” for which the enterprise has spent resources to collect and therefore it needs to be kept confidential and protected from it being stolen.
Since Data is used as a tool for business decision making, it was essential for data to be made “Reliable” for decision making and hence the Availability and Integrity was important and they became part of the CIA triad of Information Security. As the legal perspective developed, Authentication and Non Repudiation got added to the objectives.
This approach covered all data and included the “Personal Data” which was also protected.
The emergence of stringent laws such as GDPR changed the focus of Information Security and today, protecting “Personal Information” gets more attention than protecting “Information” in general. The DPO therefore is gaining more prominence than the CISO in an organization, since his role extends beyond the organization and also that under GDPR he enjoys certain immunity against management action to remove him unfairly.
As a result of the data protection regulations, the “Data Governance Framework” has to address these regulations and follow the prescriptions provided there in.
The data protection regulations like GDPR is completely devoid of a realization that “Data” is a “Raw Material” for businesses and the attempt to ignore this aspect makes the regulations impractical to be appreciated by the business managers. Though PDPA (Personal data protection act of India) is a little more considerate on the business, the window of business exploitation of “Personal Data” for business is very narrow under GDPR. The Californian Consumer Protection Law recognizes that Personal Data is a “Property” and the data subject can provide his consent for sale.
For an organization, accommodating the different personal data protection laws along with its own “legitimate interests”, is a big challenge which the “Data Governance Framework” needs to address.
It is not clear if the Kris Gopalakrishna Committee is likely to address the Data Governance in this context.
Readers of this site are familiar with the proposition of PDPSI, or Personal Data Protection Standard of India, which tries to provide a “Framework” for Personal data protection which inter-alia is a “Personal Data Governance Framework”.
Now what is required is to add the “Corporate Data Protection Standard” to PDPSI to arrive at the “Integrated Data Protection Standard which will also be the Data Governance Model for the enterprise” which has both personal data and corporate data.
The terms of reference of the committee refers to “Non Personal data” which is obviously part of the total data but is not personal data governed by the personal data protection regulations.
Can this “Non Personal Data” be considered simply as “Corporate Data” and the Data Governance model be built as a combination of “Personal Data Governance” plus “Corporate Data Governance”?… is one option which the committee can consider.
Obviously this “Corporate Data Governance” will have to focus on the CIA triad since it is the Data property of the enterprise.
However, the Srikrishna Committee which is the basis for this Kris Gopalakrishna committee as per the preamble, flagged a different aspect of Data to be brought under regulatory provisions.
The concept which the Srikrishna Committee flagged was “Community Privacy” which was the need to protect aggregated personal data. Such aggregated personal data might have been collected individually under a “Consent” regime and hence may be covered under the Personal Data Governance model which complies with the GDPR/PDPA etc.
What the Srikrishna committee was referring to was the recognition of the concept of “Dynamic Data” which we highlighted earlier and explained in the following two articles.
I request readers to spend some time trying to assimilate the thoughts that may be buried in these articles which are relevant for our discussion on what the Kris Gopalakrishna Committee is expected to do.
The basic idea I have tried to explain in these articles is that the concept of Personal Data as we now try to apply may need a re look. Personal Data is not like a PDF document that exists containing the name, address etc of an individual to be able to be classified as either “Personal data” or “Sensitive personal data” and subjected to the controls of Governance.
Within an organization, “Data is Dynamic”. It starts with a few elements of the data which soon like a rolling snowball acquires other data around it and becomes significant.
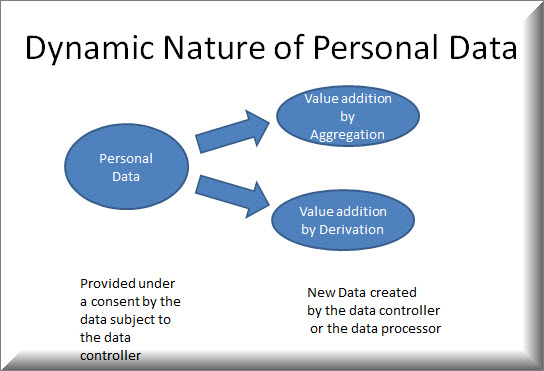
This change of the nature and value of personal data into something else by aggregation or derivation is what the Srikrishna committee recognized as “Community Data” and suggested a legislative framework to be explored beyond PDPA.
Ideally this exploration should have been entrusted to Justice Srikrishna himself since he could have then created a legislation which was seamlessly integrated to the PDPA. Instead we now have a corporate committee sitting to develop a new legislation which is a complicated legal challenge.
The industry is interested in protecting its “Right to Process Data” and make money out of it. This includes the “Right to Sell Personal Data of its customers” either in the raw form in which it is supplied by the data subjects or in a modified value added form which the enterprise develops through its own investment.
The GDPR was clearly ambiguous in its approach because it could lead to an interpretation that when the data subject requires portability or erasure of his data, it extends not only to the data supplied by the data subject but also the data derived by the organization in the form of a “Profile”.
It is in this context that we had raised the issue of if the data subject has given charcoal and the data processor has created diamond out of it, when a portability request is received, how fair it would be to demand that the diamond be returned.
The Kris Gopalakrishna Committee has to find an answer to this dilemma.
In our theory of Dynamic Data, we have also raised the issue of “Data being a stream of binary expressions” and all other forms of data are “Interpretations of the software and hardware”. We are receiving the “Consent” for the data to be used for a purpose but more often the data processor discovers new uses of the data for which no consent has been obtained earlier. GDPR simply disposes of this challenge saying that let the data processor/controller obtain new additional consent without understanding the practical difficulties in building a business with such a rigid control of purpose.
Many times, the controller/processor need not do any specific processing routine for the raw data to acquire value over time like the value of wine that increases with age. One example of this is the CEAC Drop Box concept of Naavi or even the Webarchive.org service.
Recognizing that data changes it status by efflux of time as well as by aggregation, application of data analytics etc and providing room for their usage is part of the Data Governance legislation that this committee needs to address.
Whether “Anonymization” addresses all requirements of a Big Data Company or there are specific instances under which identifiable personal data also needs to be aggregated are issues to be debated and provided for in the Data Governance Framework.
The Data Governance Framework also needs to address the “Data Laundering” that happens through mergers and acquisitions as we recently highlighted in the TransUnion CIBIL case
The Data Governance Framework also needs to address the need for “Data Sovereignty” which will have an impact on Data Localization.
Thus it appears that the Terms of Reference is too sketchy and needs to be expanded further
. At the same time, for all the issues mentioned here, the constitution of the Committee will be ill equipped to debate and arrive at the right decisions.
Now that the committee has already been announced with a former CEO of an IT Company as its head, it is impossible to bring a heavy weight Judicial person like Justice Srikrishna. But none of the present committee members represent the Techno legal experience required to interpret the status of different kinds of data and how data changes status etc.
We need to wait whether like in the case of Srikrishna Committee, it holds consultations with the public, presents a draft report for further discussion etc. On the other hand, if it just meets a couple of times and releases a NASSCOM draft as its report, then there could be conflicts with the PDPA.
Let’s wait and Watch.
Naavi
Reference




")



Pingback: Discussion on Data Governance | Foundation of Data Protection Professionals in India