In meeting with the Compliance requirements under the different Data protection regulations, organizations face one huge challenge which is to protect the Data subject’s rights of “Portability” and “Erasure” or “Right to Forget”. The problem arises because in the current systems of processing, personal data of an individual may be processed by different persons in an organization at different points of time and several instances of a single data set gets generated and stored under the control of different employees.
When a portability or erasure request has to be complied with, it becomes a difficult task to identify if all instances of the personal data is removed. If an organization has to be confident of having ported or erased the personal data of a verified data subject, it has to be certain that no other instance of the personal data remains in the organization.
One method used for this purpose could be to run a “Personal Data Discovery Search” and identify where all in the organization the personal data of the given subject resides and then collate it for porting or destruction. There are several “Personal Data Discovery Tools” that may be available for the purpose but they may not always be as efficient as we may desire.
This “Search and Collate” method is unavoidable for an organization with legacy personal data. However, organizations starting their activity in the post-Data Protection era need to think of making their work simpler since “Search and Collate” may not always be an efficient form of discovery of personal data.
Even the existing organizations can explore if they can adopt an alternate system for the future collections of personal data if available.
Single Instance Storage
One solution which companies need to think therefore is the “Single Instance Storage” of personal data as discussed here.
Under this system, an organization will maintain a single instance of a set of personal data for a given data subject and all activities of processing are carried out in such a manner that multiple instances are not created in different systems except when they are to be ported or disclosed to an entity outside the organization including the customer to whom it has been processed.
Companies mostly use “Virtualization” as a means of achieving this centralization of personal data.
Virtualization can work efficiently when the collection of personal data itself happens through a collection of a form on the web.
But if we need to ensure that the virtualization works in practice, there should also be an efficient method of managing the inflow of personal data through unstructured form in the form of e-mail attachments received by any employee of the organization.
Similarly challenge arises when during the life cycle of data processing, a Non Personal Data may assume the status of an identified data due to a specific step in processing.
In both these cases of an employee receiving personal data through his/her personal e-mail or converting a non personal data to personal data as a part of processing which he/she is doing, the generated personal data needs to be specifically committed to the centralized data storage system by the individual who first becomes aware that he is in possession of personal data.
How PDPSI addresses this need
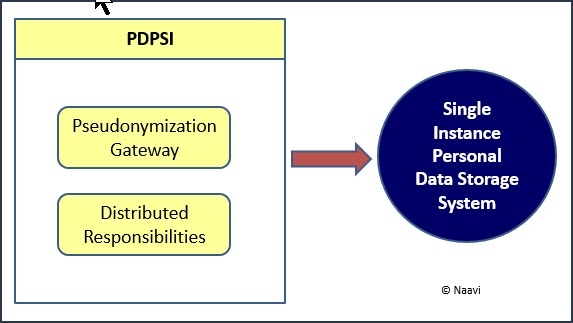
It is to enable this “Committing of Personal Data to the Central Repository” that PDPSI (Personal Data Protection Standard of India) recommends that employees of an organization need to be classified as “Internal Data Controllers”, “Internal Data Processors” and “Internal Data Disposers”.
The person who first receives the personal data in his custody or generates the personal data is the “Internal Data Controller” who has the responsibility to hand it over to the Central repository and immediately erase the instance of personal data at his custody.
The “Internal Data Disposer” is the one who deals with customer relationships and has to retrieve the processed data from the repository and send it out to an external entity. If in the process of such sending, the Internal Data Disposer has created a temporary instance in his system, it is his duty to purge it at the earliest.
The remaining employees of the organization who simply process the personal data in the repository under a virtualized system are the “Internal Data Processors” because they donot create an instance of the personal data in the systems they control.
This kind of processing constitutes “Privacy By Design” which includes the technical process as well as employee responsibility distribution.
Use of Psudonymization Gateway
If the processing is amenable for pseudonymization, then the Internal Data Controller can pseudonymize the data and release it to the Internal data processors without the need for processing in the virtualized environment. This could reduce the cost of compliance and also the dependency on the Virtualization service.
In such a system the “Processed Pseudonymized data” has to be re-identified before disposal to the customer/external entity which will be done by the Internal Data Disposers.
Where a Pseudonymization gateway system has been introduced instead of the Virtualization environment, the Pseudonymization department will act as both Internal Data Controller and Internal Data disposer. They alone control the mapping of real identity vs pseudo identity which has to be protected in an appropriate manner.
Thus the need to comply with Portability and Erasure of personal data is effectively addressed in the PDPSI system suggested by Naavi as “Single Instance Data Storage System” as a combination of “Pseudonymization Gateway” and “Distributed Responsibilities” .
Naavi




")


