P.S: This is a long post and addresses multiple objectives. Firstly it responds to a report which appeared in Medianama.com on what transpired at the JPC deposition to correct some misconceptions. Secondly it tries to explain the difference between de-identification and anonymization about which confusion prevails with many law makers and judicial experts. Thirdly it also clarifies the seggregation of roles between the past legislation of ITA 2000, present legislation of PDPA and the future legislation of NPDGA.
MediaNama Comments
The introduction of the Kris Gopalakrishna Committee report (KGC) has opened up many interesting but basic debates one of which is on the concept of “Anonymization”.
Medianama.com which is one of the well known critics of Government policies made a comment regarding the deposition made by the undersigned before the JPC on PDPB 2019 on August 10,2020, in which it stated as follows:
“FDPPI spent much of their 90 minutes discussing what anonymisation means, how it works, and potential privacy harms associated with it, five sources told us. Members of the committee asked questions about whether anonymisation was enough to protect people’s privacy, and if de-anonymisation posed a significant risk to users, two sources told us. FDPPI had proposed that the same data fiduciary that anonymises data should not be penalised for de-anonymising such data, three sources told us. According to the Bill, only re-identification of de-identified data (Section 82) is considered an offence. Re-identification of data as an offence was briefly mentioned but not discussed at length.
Despite extensive discussion of anonymisation and anonymised data, the Committee of Experts’ report on governance of non-personal data was only name-checked in that it exists, two sources told us. It was not discussed since members agreed that non-personal data did not fall within the mandate of the Personal Data Protection Bill.
Three sources also confirmed to MediaNama that the FDPPI expressed its support for exemptions granted to government agencies from the provisions of the Bill under Section 35, but the Committee paid no heed to it.”
It may be noted that the discussions were supposed to be confidential and it is surprising that such discussions are being reported regularly by Medianama. However, as long as the report is accurate it is merely a breach of propriety but if there is any error in reporting even if it is a genuine mistake, there could be some unpleasantness.
Since comments have been made on my deposition, some clarifications may not be out of place. Further, in the discussion on the KGC report Justice Srikrishna also had expressed certain views which related to the concept of “Anonymisation”.
In this context, let’s discuss the distinction between Personal and Non Personal da onta and how Anonymization fits into the discussion.
In order to explore the concepts, we may refer to Naavi’s Data Theory . This was first published in October 2019 before PDPB 2019 was released and has several thoughts which have become more relevant today after the KGC report has been released.
(All the articles about the theory of data can be accessed here)
The Boundaries between ITA, PDPA and NPDGA
In this discussion, we need to consider three legislations, namely Information Technology Act 2000 (ITA) which is already in existence, Personal Data Protection Act (PDPA), which is in the final stages of being passed and the Non Personal Data Governance Act, (NPDGA) which is in the preliminary stage of conceptualization.
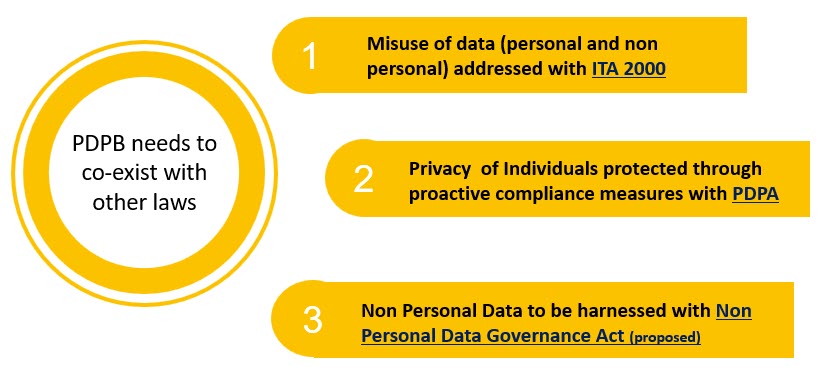 All the three legislations namely ITA, PDPA and NPDGA address “Data or Information” and represent the Past, Present and future of legislation related to a set of binary expressions called “Data” capable of being interpreted in a device called Computer and stored, transmitted, aggregated and modified.
All the three legislations namely ITA, PDPA and NPDGA address “Data or Information” and represent the Past, Present and future of legislation related to a set of binary expressions called “Data” capable of being interpreted in a device called Computer and stored, transmitted, aggregated and modified.
Data is created by technology as a sequence of binary expressions and interpreted by the humans with the use of technology that converts the binary information into a human experience-able form of text, sound or image or a combination thereof.
Data does not know if it is Personal, Non Personal, Sensitive, Critical etc. These are the interpretations humans. It is the challenge to the law makers to ensure that when introducing legal prescriptions on the interpretation of Data, a reasonable clarity is provided on the context in which a particular law is applied. This clarity is achieved through the various definitions.
Definitions of terms as defined in the law define the applicability of the law and the contours of the boundaries of any law.
Section 3(11) of PDPB 2019 defines data as
“data” includes a representation of information, facts, concepts, opinions or instructions in a manner suitable for communication, interpretation or processing by humans or by automated means;
Section 2(1) (o) of ITA 2000 which should be considered the father of PDPA defines data as follows:
“Data” means a representation of information, knowledge, facts, concepts or instructions which are being prepared or have been prepared in a formalized manner, and is intended to be processed, is being processed or has been processed in a computer system or computer network. ,.and may be in any form (including computer printouts magnetic or optical storage media, punched cards, punched tapes) or stored internally in the memory of the computer;
The definition of data in the parent legislation is more detailed and PDPB 2019 adopts an inclusive definition.
The ITA 2000 is more fundamental as it goes into how “Data” originates as a representation that can be interpreted by a computer system (which itself is defined as a device that functions by manipulation of impulses). The inclusive definition of PDPB adopts the ITA 2000 and does not re-interpret it.
The NPDGA is a law which addresses “Data which is not personal data under PDPA” and hence the definition of data under the ITA 2000 extends to NPDGA also.
Having recognized that data in all forms is a “Binary Sequence”, the interpretation of something being “Personal” is derived from Section 3(28) of PDPA as
“data about or relating to a natural person who is directly or indirectly identifiable, having regard to any characteristic, trait, attribute or any other feature of the identity of such natural person, whether online or offline, or any combination of such features with any other information, and shall include any inference drawn from such data for the purpose of profiling;”
While defining personal data we include the “Offline” information and “Inference”. This pre-supposes that a human is looking at the binary form of the data through the converters called the computers, software applications and hardware peripherals.
What this means is that the definition of what is personal or non personal is relative to the knowledge and capability of the person who is looking at a data.
What is “Personal Data” for A may be not so for “B”. Hence any interpretation of data as personal or non personal has to be based on what a “Prudent Man under similar circumstances” understands.
On either side of this “Prudent man” are people who are not adequately informed to interpret and people with X-ray eyes who can look beyond the obvious.
Law however can only address itself to the middle where a “Person with reasonable information and knowledge considers it as Personal Information”.
One example is to go to Timbuktu and give a person a piece of paper on which it is written “MODI” and give the same chit to a person in Delhi (let’s forget the language issue now). A reasonable man in Delhi is expected to interpret the data as “Personal”. But a “Reasonable man in Timbuktu” is not required to interpret it as “Personal”. Hence when a law is made for India and Timbuktu together, it is difficult to ensure that data will remain “Personal” or “Non Personal” for all the stake holders.
I am quoting this example because today there is a discussion about how do we define “Anonymisation” which is the boundary between PDPA and NPDGA as well as ITA 2000 and PDPA.
ITA 2000 today addresses all aspects of data governance and data security and applies both to personal data and non personal data. PDPA is trying to pluck out ” Parts of Protection of Personal Data” from ITA 2000 and take it over to PDPA. PDPA will focus on “Due Diligence” and “Reasonable Security Practice” as defined in Section 43A of ITA 2000 and does not address “Cyber Crimes committed with personal data” which will continue to be addressed by ITA 2000.
Hence Personal data as defined in PDPA continues to remain defined as “Data” for the purpose of application of ITA 2000.
While PDPA defines the proactive compliance requirements that a Data Fiduciary or a Data Processor should follow, any misuse of personal data (Other than what is indicated in Section 82 of PDPA) remains within the jurisdiction of ITA 2000.
Two elements have to be considered therefore to distinguish between what data comes under ITA 2000 and what data comes under PDPA.
They are
-
- Data becomes personal because the Data Fiduciary can identify a “hidden natural person associated with the data”.
- Issue comes under PDPA for the purpose of compliance of obligations etc stated in the Act and not when a wrongful harm has been caused in contravention of the law (Section 82 excepted)
On the other hand, the boundary between PDPA and NPDGA is defined by the following criteria
-
- Data which is not personal data as per PDPA belongs to NPDGA regulation. NPD may also arise separately when data originates without being identified with any natural person.
- Issues of misuse of NPD comes under ITA 2000 (subject to any specific offences that may be defined under NPDGA like section 82 of PDPA)
- NPDGA is focussed on “Unlocking the value inherent in the Non Personal data” and not in “Protecting the Non Personal Data”.
The issue of Anonymization
There is a misconception in many that “Non Personal Data” is only generated from Personal Data. This is wrong and has to be corrected.
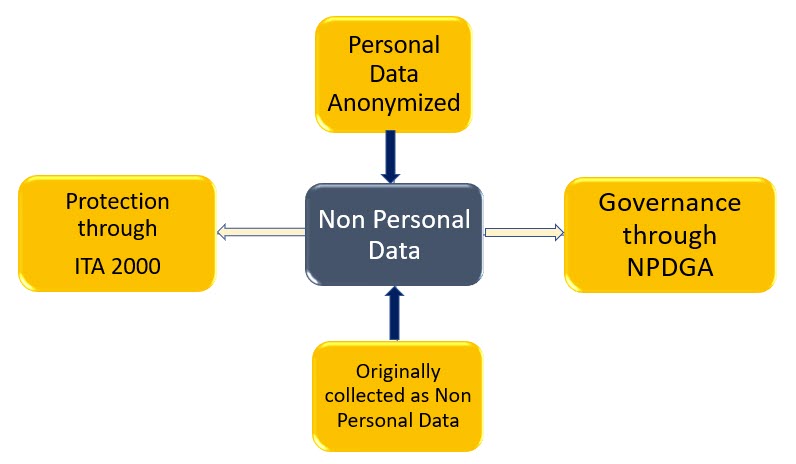
There is no doubt that Personal Data which is “Anonymized” flows into the ” Non Personal Data” category.
But there are also other kinds of data which takes birth as Non Personal Data directly. One example is the weather data captured by sensors. If I say temperature in one of the sensors in Bengaluru Airport shows 27 degrees, this is not personal data.
However, the person who has installed the sensor which could be the Government or an individual may claim a right on the data captured because he has invested money to get that data. It is this ownership that NPDGA tries to recognize and call as “Public Data” or “Private Data”.
Some data also arises because of the shared activity of a community.
One example of such data (in a gated community data collection system), is the following data:
“between 10.00 am to 11.00 am , 50 vehicles passed through the toll of which 28 were cars, 12 were two wheelers and 10 others.”
Since this data collection device/system is funded by the society, this data belongs to the community. Each person who is driving out or in, may claim that the information that he drove out or in is his personal data.
But what is being represented as community data is not that A, B or C drove out in a Car and D, E or F drove out in a two wheeler, but so many vehicles drove out or in.
This is the “Community data” for which NPDGA recognizes the community as the owner for which there will be a “Data Custodian” as a representative of “Collective ownership”
The PDPA has no stake in either weather data collected by the Government or a Private company nor the community data collected by the building society.
If the building society is maintaining a register where the vehicle numbers are being noted along with the names of passengers, that register represents an aggregation of personal data and is within the provisions of PDPA.
But if that data is extracted out into another register and the name and vehicle number is masked and replaced with a serial number 1, 2, etc., then the data becomes “de-identified”.
The information “vehicle 25 moved out at 10.40” is de-identified data.
If instead of replacing the name and vehicle number with a serial number, the name is replaced with another random alpha character and vehicle number is replaced with another random alphanumeric character, then the information generated looks like a normal information that xyz with vehicle number AB25M2020 moved out. But this is “Pseudonymized” and is not revealing the identity of the individual who moved out.
PDPA recognizes that de-identification and pseudonymization are tools of securing the information when it has to be processed by many people to regulate the “distribution of information within an organization on a need to know basis”.
This is however, not “Anonymization”.
In the case of de-identification or pseudonymisation (PDPA does not distinguish between these two), there still exists a “Mapping record” from which the organization can re-identify. For example if the security manager of the building society wants to know what are the details of vehicle number 30, it can be fetched and provided.
This is what can be called as “Re-identification within a process” which is not an offence under Section 82 of PDPA. However, if the society has disclosed its traffic data in a de-identified form to some body else for a purpose, and that person uses his intelligence or some other information available to him and is able to identify Vehicle number 30 was of Mr Raja, then this Re-identification comes under Section 82.
(P.S: The MediaNama report had not properly represented FDPPI suggestion in this regard.)
The issue of “Anonymization” and “De anonymisation” is different from De-identification and Re-identification.
Anonymization by definition is an “Irreversible Process”.
Conceptually, Anonymization is computationally infeasible to be de-anonymized” and it is impossible to extract personal data out of anoymized data by any reasonable effort.
If however there are “Hackers” who are determined and can “De-Anonymise”, they are not different from hackers who break a password or encryption. Law can only set some minimum standards of security but cannot prevent a determined hacker from criminally extracting information which has been anonymized. Law has to take stringent measures to create deterrence of such activities.
Presently Section 82 applies to “Re-Identification of a de-identified personal data”.
PDPA assumes that since it has defined “Irreversible conversion of identifiable personal data into anonymized data” takes the data out of the purview of PDPA, what a criminal may do with such anonymized data is to be handled by ITA 2000 and not PDPA.
The de-anonymisation of anonymised data can be brought under Section 43 and Section 66 of ITA 2000 and relief would be available to the data principal.
If a certain anonymised information is de-anonymised, it also reflects on the quality of anonymisation process adopted by the Data Fiduciary. If the Data Fiduciary has met the standards of irreversibility that the DPA has prescribed and still the anonymised data has been deanonymised, then the Data Fiduciary cannot be held responsible. Otherwise he can be accused of “Negligence” and can be imposed administrative fines for wrongful disclosure of identifiable/ or de-identified data as anonymised data.
Note on the JPC discussion and MediaNama comment
The discussion with the JPC on Anonymisation was to answer the questions related to the distinction between De-identification and Anonymisation and consequently Personal Data and Non Personal Data.
We should be happy that the members were patient enough to listen and discuss this conceptual issue and gave an opportunity for us to contribute to the education of the members. This is precisely the purpose of JPC inviting experts to explain on such technical issues.
JPC is not a forum where our business interests are to be taken for being incorporated in the law as some other organizations representing business interest may consider. That is called “lobbying”.
FDPPI was not into “Lobbying” but in “Providing clarifications for the questions asked and hence there was and will be no expectation that our views are to be immediately accepted by the Committee or not.
The comment of Medianama that “Committee paid no heed to the recommendation of FDPPI” is also not a proper way of putting things again for the reasons stated above that the JPC discussion was a “Deposition as an expert” and not a self centered request.
There was no need for the JPC to say, they agree or disagree with any presentation. They are expected to listen and absorb knowledge that experts can bring to the table and use their discretion when they finalize their recommendations. Hence we are perfectly fine with the opportunity provided to present our views and not unduly concerned about the reactions.
Also, we neither confirm or deny what MediaNama has stated on the confidential proceedings in the Committee and provided this clarification only to clear the wrong perceptions which the MediaNama report could have created.
I have also used the opportunity to provide some knowledge inputs as I think is correct from the Jurisprudential point since even judicial experts appear to have difficulty in accepting that de-identification and anonymisation are two different concepts.
Concept of Unlocking
Now looking at the objective of NPDGA, several loose comments have already started floating around that this Act will enable Government to appropriate data built by private sector at a cost, it will use its power to deny IPR etc.
I would like all experts to take into account that at present the expert committee has just provided its report which the MeitY has placed before the public without any of its comments. It is possible for the MeitY to modify it as they like. It is presently in a very preliminary state and is yet to be converted into a Bill.
At this time what is required for experts is to put their comments on the report of the committee and let the MeitY have more information with which a version of the Bill can be developed. This is more like a brain storming exercise and not an exercise to criticize the KGC report as if it is a bill about to be passed along with PDPB.
In this respect we need to only look at the objective of the Bill and make broad recommendations if we have any.
In my view the proposed NPDGA is an attempt to unlock value to a part of data which today has zero value to either the Government or the community which contributes to the generation of NPD. Only a few intelligent companies are harnessing such data and making commercial value out of it. These companies who are the biggies like FaceBook, Google etc are expanding their hold on NPD in such a manner that smaller entities have no opportunity to exploit the same.
The NPGDA would be an attempt to ensure that there is a fair mechanism that those who contribute to the generation of the NPD are rewarded by enabling the custodians of community data to realise value. Government on its part may place some data in public hands through the “Open Data” Concept.
In between if the Government feels that some data has been acquired by the Private entities from public resources, it may acquire the data at a fair cost. Only if the data is related to national sovereignty issues, it may exercise the “Compulsory acquisition” option.
Where there is an IPR for the private party and the data is not in national interest to be acquired, Government cannot force the IPR owner to give up the right and hand over the data. Any speculation in this regard is not backed by reason.
Presently IPR laws such as patent laws do have a “Compulsory licensing” clause and a similar provision may be made in the NPDGA. It would be backed with a due process as well.
Hence the criticisms of NPDGA (Proposed) is premature. We have discussed this issue at present only because people who donot understand the firewall between PDPA and NPDGA created by Anonymization are discussing “Consent for Anonymization”.
While it is possible for a Data Fiduciary to take consent for Anonymization along with the consent for use, in our opinion this is not necessary.
Anonymisation is a legitimate interest of the data fiduciary and does not require consent or explicit consent. Anonymisation itself is not a “use” and post anonymisation the data is no longer under PDPA.
De-identification on the other hand is a technical process of in-process security and does not require specific consent.
Those data fiduciaries who donot want to anonymize and place the anonymized data in Government hands are welcome to keep the data in personal data form itself and delete it if the purpose of its collection is over. In such a case, as per the present PDPB or KGC report, the Government may not be able to force the personal data owning data fiduciary to anonymize and hand it over to the Government.
Naavi
(Comments are welcome)




")



Let us have common Agency to control the Data Ocean
The author has wonderfully clarified that the definition of ‘data’ as enacted in the Information Technology Act 2000 is the basis for ‘data’ covered in the proposed PDPA, which has been further improvised to define data covered under PDPA, to be those which are with personal identifiers. This clears the confusion that prevailed in the minds of the stake holders that ITA 2000, proposed PDPA and coming up NPDGA laws are on different footings, which is far from truth as the deliberations indicate.
The process of removal of identifiers from the source data containing personal data with identifiers to form de-indentified data doesn’t mean that the same has become Anonymised data. It becomes Anonymised if and only if it cannot be re-identifiable to get the original data with personal identifiers. The de-identified data that can be re-identified with identifiers data are mere psedunomus data which are still covered under the ambit of PDPA has been explained with simple, but effective examples. Anonymization is computationally infeasible to be de-anonymized. The words of NAAVI, “Data does not know if it is Personal, Non Personal, Sensitive, Critical etc. These are the interpretations humans.” rekindles the need of philosophical approach to understand the ocean in the making and configuration that could be named as DATA MAHASAGARA. This is a master piece by NAAVI JI.
But the concern for the citizens here is, do we require or afford, or is it tolerable to have three different Authorities to take care of the three laws, built on the same data foundation, that are in the process of coming. In other words, can we bear (i) an Authority to manage The Information Technology Act, covering all data related activities and enforcement of civil and criminal remedies of offences listed therein [already in existence],(ii)a Controller of personal data under PDPA for protection of privacy of the principal and (iii) another commercial data Controller for non-personal data governance or regulations or rules or act, [may be called by any such name] that is proposed to use the non-personal data for commercial purposes by all . The burden to run such parallel agencies is a demanding proposal to the country like India as the expenditure on NPA is an ever growing concern. The more worrisome part is that the conflicts that may arise between these agencies and a suitable resolution mechanism to be in place. This may disrupt the commercial activities of the country, which is much more important in these days of globalization and severe competition among nations. The Justice delivery system in the Country is already under tremendous pressure due to mounting of pendency of litigations. Therefore I am of the opinion that there should be only one agency taking care of all these three laws relating to data and their process and communication operations in the country. As the basis for all these laws are the same it makes sense to have only one agency to manage it for the entire country. This may help the bringing efficiency in the already existing authorities in implementation of IT Act.
M G KODANDARAM, IRS, ASSISTANT DIRECTOR (NACIN) RETIRED