(This is in further continuation of the previous article on definitions in the SC draft regulations)
The draft Supreme Court Regulations for the Use of Artificial Intelligence in Courts, 2026 (SCAIF) appears to treat “Sensitive Judicial Data” as a proxy for privacy risk and “Court Data” as a proxy for operational ownership.
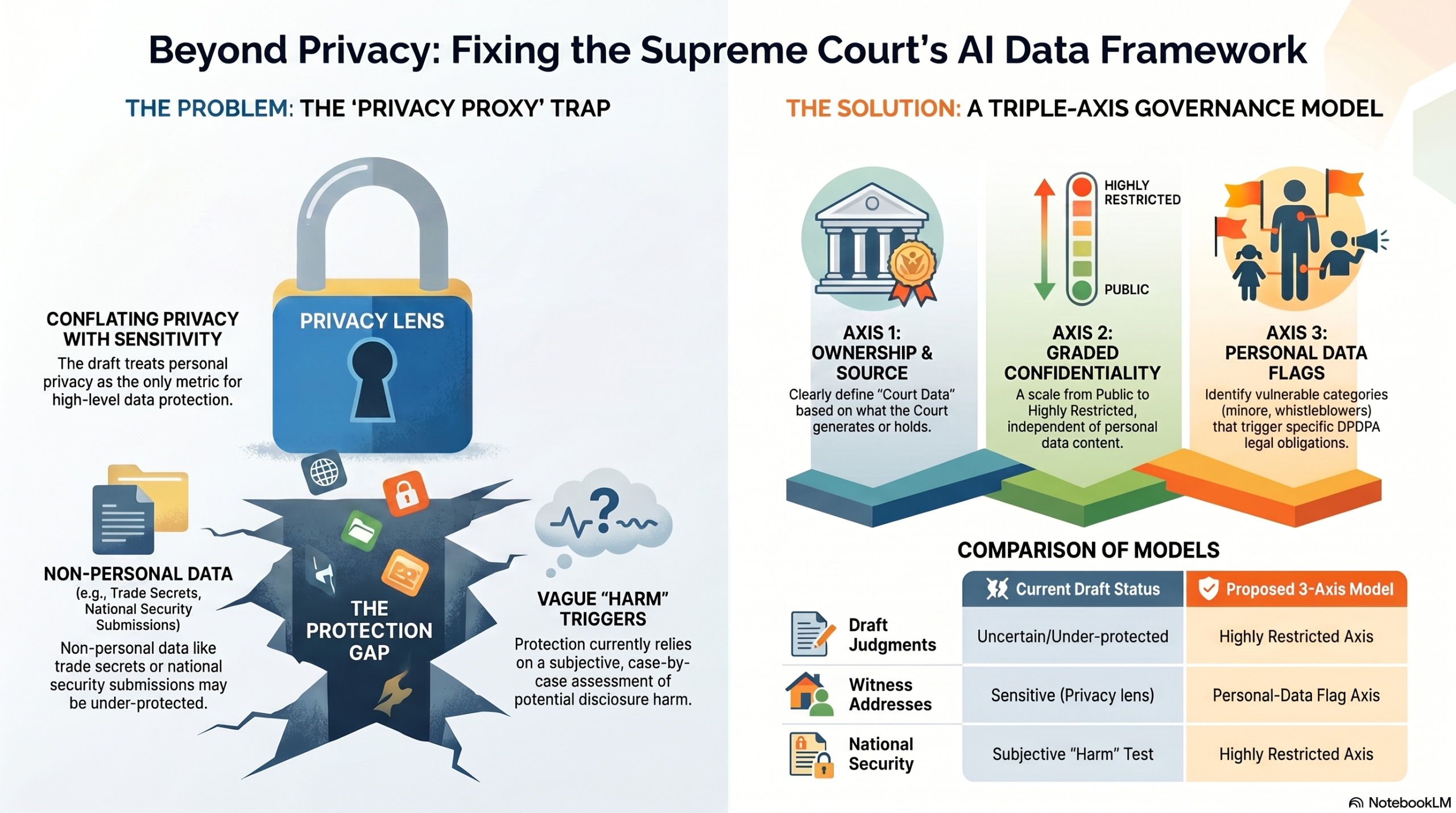
These are two genuinely different ideas, and by mapping its protections onto them, the draft ends up conflating privacy-sensitivity with judicial-sensitivity.
The consequence is that some judicial information may be over-protected with measures designed for personal data, while other information — sensitive for reasons that have nothing to do with privacy — may be under-protected. Almost every inconsistency in the drafting flows from this single confusion.
What the draft actually says
Three definitions matter. “Data” carries the same meaning as in Section 2(h) of the Digital Personal Data Protection Act, 2023 — “a representation of information, facts, concepts, opinions or instructions in a manner suitable for communication, interpretation or processing by human beings or by automated means.”
“Court Data” is defined broadly and by source: any data generated by, or in the possession of, a Court. It is, in effect, an ownership concept.
“Sensitive Judicial Data” is defined differently. It covers (i) any personally identifiable information of parties, witnesses or legal representatives, and (ii) any information processed in connection with a Court process, the unauthorised disclosure of which may cause harm. “Court process” is itself drawn very widely, extending to filing, scheduling, hearing management, evidence handling, legal research, drafting, translation, transcription and record management. “Harm,” meanwhile, is defined to include damage both to the reputation or rights of an individual and to those of an institution.
The ambiguity is in the trigger, not in an omission
At first glance it appears that litigation content , pleadings, written arguments, judicial notes, draft orders, evidentiary records — has simply been left out of “Sensitive Judicial Data.” But part (ii) of the definition, read together with the expansive meaning of “Court process,” may be argued as including such content.
The real problem is subtler. Whether litigation content qualifies turns entirely on a vague and subjective test — whether its “unauthorised disclosure may cause harm” — and it is not even clear whether that harm qualifier attaches only to part (ii) or also governs the personal-information . So the question is not whether pleadings and draft orders are categorically excluded, but on what uncertain basis they are sometimes in and sometimes out. A definition whose reach depends on a case-by-case harm assessment, undefined in method, is a fragile foundation for a protection regime. That is the ambiguity that needs fixing .
The mismatch this produces
The drafting consequences confirm the diagnosis. As the draft is structured, Sensitive Judicial Data is accorded the highest standard of protection under Section 10. Section 46 brings both Sensitive Judicial Data and Court Data within purpose limitation, but does not subject either to sovereign-cloud deployment. And Section 48’s data-localisation requirement is applied only to Sensitive Judicial Data — which, on the privacy-led reading, may exclude precisely the non-personal litigation content one would most expect to keep on Indian soil.
The clearest way to see the gap is to imagine material that is highly sensitive yet contains no personal data at all such as a draft judgment leaked before pronouncement, a judge’s deliberative notes, a sealed-cover national-security submission, or a trade secret disclosed in a patent dispute. None of these is obviously “Sensitive Judicial Data” under a privacy lens, yet each demands the very highest protection. If localisation and sovereign-cloud obligations track a personal-data concept, this category can slip through — protected, if at all, only by the discretionary harm test.
Why there is a problem
There may be a reason behind the choice. Personal data is where the DPDPA’s liability actually bites; tying the strongest safeguards to personal information aligns the regulation with the statute that will be enforced against the Courts as data fiduciaries. That is understandable. But judicial information is sensitive for reasons that extend well beyond privacy, such as, evidentiary integrity, judicial confidentiality, institutional security and national interest among them. A framework that measures sensitivity primarily through a privacy lens will systematically misjudge the material whose sensitivity has a different source.
The harder questions the classification must answer
A coherent scheme also has to take a position on open justice, which a privacy-led definition tends to obscure. The open-justice principle, reflected, for the Supreme Court, in Article 145(4) of the Constitution means that judicial records are not confidential by default merely because they contain personal information. Once such records are lawfully in the public domain, restricting access to them should ordinarily require a specific justification: privacy, security, victim protection or an overriding public interest.
It can fairly be argued that merely filing a petition does not place the petitioner’s data “in the public domain” in the full sense, and that an in-camera hearing changes the position entirely. But absent such circumstances, there is little logic in treating every petitioner as automatically entitled to confidentiality under privacy law. The masking of data relating to women and minors, including in matters concerning the commission of offences, and not only where they are victims , is sometimes defended under a “right to be forgotten.” It is worth being candid that this right, in the context of court records, is unsettled in India and applied inconsistently across the High Courts; it is judge-made rather than clearly statutory. And it carries a real cost: indiscriminate masking degrades the accuracy of the judicial record for legitimate research. A more disciplined approach would confine masking to the data of victims and similarly vulnerable persons, rather than extending it to petitioners as a class.
Those vulnerable categories themselves deserve explicit treatment. The personal data handled by Courts is not uniform. The data of minors, of whistleblowers (who face retaliation risks that ordinary witnesses do not), and of foreign nationals (whose information raises cross-border-transfer and diplomatic dimensions under Section 16 of the DPDPA) all warrant differentiated handling. A flat “personal information” category cannot capture these gradations.
A more coherent model
The fix is not to abandon classification but to stop loading two different ideas onto one ladder. The draft’s instinct to separate ownership (“Court Data”) from sensitivity is correct; the trouble is that its sensitivity concept is really a privacy concept in disguise.
A cleaner model would classify information along clearly distinct dimensions:
First, ownership and source — the “Court Data” axis, identifying what the Court has generated or holds.
Second, confidentiality level — a graded scale running from Public, through Confidential and Restricted, to Highly Restricted. This is where draft judgments, deliberative notes and sealed-cover material belong, regardless of whether they contain personal data.
Third — and this is the dimension the present draft folds into the second , a personal-data attribute that cuts across the confidentiality scale, flagging information governed by the DPDPA and identifying its vulnerable subcategories (minors, victims, whistleblowers, foreign nationals and the like). A public judgment that happens to name a minor is still “Public” on the confidentiality axis, but carries a personal-data flag that triggers specific obligations. Treating personal-data status as a rung on the confidentiality ladder — as the current drafting implicitly does — simply repeats the original conflation.
Keeping these three apart lets the regime do what a single concept cannot: protect a non-personal draft judgment as fiercely as it protects a witness’s address, while still allowing a public judgment to remain public.
In summary it can be stated, The classification of judicial data should be harmonised with the principles emerging from the DPDPA, 2023 and the Information Technology Act, 2000, while recognising that judicial information governance extends beyond personal-data protection to encompass evidentiary integrity, judicial confidentiality, institutional security and national interest. The definitions of “Court Data” and “Sensitive Judicial Data” — and the protections in Sections 10, 46 and 48 that depend on them — would benefit from being revisited and re-anchored in a comprehensive judicial information governance framework, one that distinguishes clearly between privacy-sensitivity and judicial-sensitivity rather than blurring the two. The draft has identified the right problem. It now needs the right axes to solve it.
Naavi




")


