(Here are some emerging thoughts on Privacy meant for further discussion during IDPS 2021…Naavi)
Indian Data Protection Law in the form of PDPB 2019 is unique for the introduction of the concept of a Data Controller being a Data Fiduciary and Data Subject being a Data Principal.

The difference in the naming of Data Controller as Data Fiduciary is indicative of the fact that the Data Controller is a trustee for the information shared with him. This imposes a responsibility higher than what a “Data Controller” is expected to shoulder. Since the Data Fiduciary is a trustee, the consent document is an indicative trust deed and there is a duty cast on the Data Fiduciary to take decisions in the interest of the Data subject who is aptly renamed as “Data Principal”.
Additionally there are a few more nuances in PDPB 2019 which we need to take note of.
The Privacy By Design policy as envisaged in PDPB 2019 is to be submitted to the Data Protection Authority and certified along with a DTS (Where possible) is like a Prospectus instrument for the raising of “Personal Data” from public for being used for business similar to the prospectus for IPOs with a “Rating”.
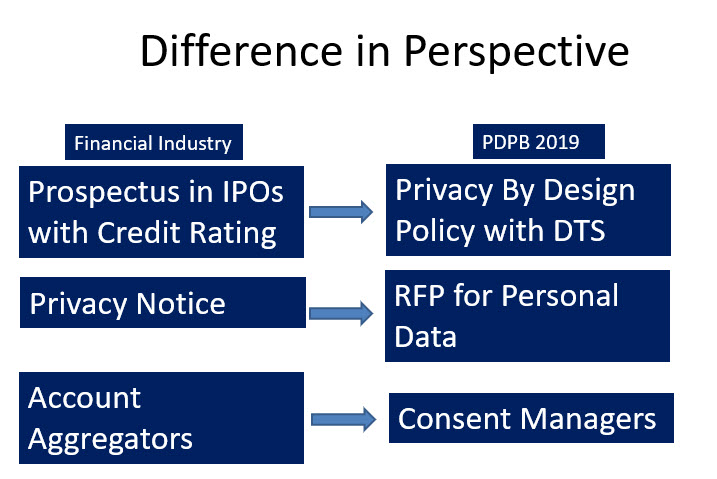
In this context the “Privacy Notice” is like a Request for Proposal (RFP) based on which the data principal provides his personal information to the data fiduciary.
In a financial IPO, there is a return expectation from the investment. In the Personal Information sharing by the Data Principal the return is in the form of the service benefit that the Data Fiduciary offers.
The RBI has now adopted the DEPA (Data Empowerment and Protection Architecture) where in the term “Consent Manager” has been used. PDPB 2019 also uses the term “Consent Manager”. However the two concepts have a slight difference that needs to be appreciated.
Under RBI’s AA proposal and the DEPA, the “Consent Manager” is an intermediary of information transmission from the Data Provider to the Data User. However under PDPB 2019, the consent manager is a data fiduciary himself and acts as a repository of personal information on behalf of the data principal and provides it on his discretionary control to the data fiduciary.
Since the “Consent Manager” under PDPB 2019 has visibility to the personal data, he has the responsibility of a data fiduciary. On the other hand the Consent manager under DEPA does not have the visibility of the information and acts only as a technology platform for transmission of identifiable personal information.
Concept of Privacy 1.0 and Privacy 2.0
In our previous article “New Dimensions of Privacy on the horizon” Naavi extended his Theory of Data to re-defining the concept of Privacy by calling the present definition as Privacy 1.0 and indicating the need for a new definition Privacy 2.0. To some extent this need is reflected in the difference between the two types of Consent Managers envisaged under DEPA and PDPB 2019.
Under Privacy 1.0, the “Right to Privacy” is the “Right of Choice of a Data Principal to determine how his personal data would be collected, used and disposed of by a third party who could be a human or an automated device”.
Under Privacy 2.0 a case was made out to recognize that there are technology processes which may convert the identifiable personal information to a state where there is no identification of an individual.
Hence a proposition was made that Visibility of identity by such automated processes should not be considered as equivalent to “Access of identifiable personal data by a human being”.
In other words, this definition of Privacy 2.0 “Excludes” processing by an automated device where the output is anonymized as per the standards to be fixed by the Data Protection Authorities.
Data Conversion Algorithms
The technology process which converts identifiable raw personal data to anonymized processed data is a combination of “Anonymization” and “Further processing”.
The “Anonymization” process is a process where the identity parameters are segregated from a data set and irrevocably destroyed. Subsequently the data may be processed by another process such as filtering, aggregation etc
(The De-identification and Pseudonymization process are similar processes where also the identity parameters are segregated but are not destroyed. They are kept separately and a mapping proxy ID is inserted to the data set in replacement of the identity parameters removed therefrom. Some consider that anonymization is also reversible and hence there is not much of a difference between Anonymization and Pseudonymization. However, reversing anonymization is like decryption of encrypted information. It is possible but rendered infeasible except under a special effort. If such effort is malicious, it is considered as a punishable offence. Pseudonymization is however a security process to mitigate the risk of compromise of identifiable data and by definition is reversible and reversal is not an offence… Naavi)
There are however a number of other data processing techniques where the input is personally identifiable data but the output is non-personally identifiable data. This process is anonymization plus one or more other process involving aggregation, filtering etc.
Big Data Companies need to use such processes for adding value to the data. After such a process, the processing company or the algorithm can either destroy the identity parameters irrevocably or retain it in a mapped proxy form. Such destruction of identity may be embedded in the process itself so that there is no visibility of the identity at any point by a human being.
Accordingly the process can be termed is “Anonymization plus” and can be kept out of privacy concerns.
This automated process is considered “Processing” under the GDPR like data protection laws and not considered as an anonymization like activity. There is a need for rethinking on this concept.
It is considered that anonymization converts “Personal Data” to “Non Personal Data”. As long as Anonymization is meeting the standards fixed by the Data Protection Authority, it should be ideally recognized as the “Right of the Business”.
It is a legitimate claim of a business entity that if the Business entity (Data Fiduciary) can effectively anonymize the personal data, they should be allowed to use the anonymized personal data for any purpose with or without consent for anonymization from the data principal.
This principle is similar to the Banking principle where the depositor lends the money to the Bank with a right to demand its return but cannot interfere in the activity of the Bank that they should lend it only to such and such a person or purpose. This reflects the principle of “Fungibility” of the money in the hands of the Bank.
The Privacy laws seem to however think that “Personal Data” is deposited for a specific purpose and hence are not considered fungible. There is a need to change this perspective and consider that after anonymization, the resulting data should be considered as the property of the data fiduciary and fungible with the rest of the anonymized data in his hands which all become “Non Personal Data”.
Perhaps, it is time that the professional community starts discussing the principle of Privacy 2.0 which provides some benefits to the Big Data Industry without sacrificing the Privacy Interests.
Presently the requirements for processing of personal data through the “Anonymization plus” processes can be incorporated in the Privacy Notice/RFP for Personal Data. However it would be good if it is formalized by recognition of Privacy 2.0 principles in the data protection regulations itself in the next available opportunity.
Naavi urges the professionals who discuss different aspects of privacy in IDPS 2021 to consider throwing some light on the above emerging thought.
Naavi




")


