“Johari Window” is a well known principle used by behavioural scientists and known to most of the Corporate managers. The recent happenings in the Supreme Court of India indicate that the Judges who head constitutional benches need to be given a lesson on what this concept means. Mr K.K. Venugopal, the Attorney General, Mr Abhishek Manu Singhvi and most importantly the fire brand TMC MLA Ms Mahua Moitra should also be invited to a workshop on Johari Window to make all of them realize how they are together mis-interpreting the UIDAI and I& B Proposal on Media Monitoring.
However, the situation is like the proverbial “Emperor’s New Clothes” . Nobody dares to use their “Freedom of Expression” which is a fundamental right guaranteed by the Indian Constitution to tell either the Judges, or the Senior advocates that their perception on what constitutes “Media Monitoring” and how it is not amounting to “Surveillance on the Citizens” and why the RFP on media monitoring cannot be considered as an attempt to infringe on the privacy of Indian Citizens and more particularly that of the petitioner.
However, in the interest of Justice and fair play, some body has to bell the Cat…. the Cat called “Privacy” which seems to be able to approach business from any direction and in any form. Even after the specific law will be passed in India for this purpose based on the Personal Data Protection Act 2018, (PDPA 2018) “Privacy” would continue to be used as a a convenient political stick to beat the Government at the pleasure of the opposition parties. The Privacy activists therefore are unhappy to bind the monster called “Privacy” into a framework called “PDPA 2018” and are using all means to oppose the passage of the Privacy Act.
Keeping the PDPA 2018 opposition to a different discussion, let us now focus on what is Johari Window and why there is a need for the Supreme Court to understand it.
According to the Google and Wikipedia,
The Johari Window is a technique that helps people understand their relationship with themselves and others.
All of us whether we are citizens of India or the politicians or lawyers or Judges in the Supreme Court of India, need to make continuous efforts to know ourselves and others better because it is an eternal need of a human being from birth to death. Unfortunately, in most of the humans, self realization dawns only on the deathbed. The Shivaparadha Kshmapana Stotra and BhajaGovindam created by Adi Shankaracharya amply captures this human tendency to ignore truth until it is too late, though it is stated in a different context.
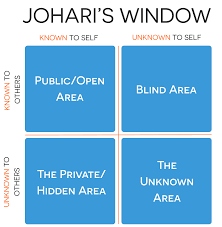
The psychologists Joseph Luft and Harington Ingham propounded the principle of the “Johari Window” way back in 1955. The essence of the theory is that the awareness grid of human beings can be classified into four zones as represented in the diagram shown here.

The Johari Window concept illustrates a simple method to recognize that in order to improve our relationship with others, we need to be aware that there is a “Blind Area” about ourselves which others know but we ourselves donot know. This is what needs to be addressed in the UIDAI RFP.
The area about ourselves which is known to us and also known to the world is the “Public” domain.
The area which is known only to us and not to others is the zone of “Privacy”.
The Privacy zone is the one which the law of Privacy should protect and prevent information to move from this privacy zone to the Public zone. On the other hand, it should be the endeavor of every responsible individual or corporate to ensure that the “Blind Zone” is made smaller and smaller by moving what others know about ourselves which we ourselves donot know to the zone of “Public” which is known both to self and others.
( P.S: I admit that this applies as much to me as an author of this article and welcome constructive suggestions. But self improvement presupposes that the ignorant seeks the knowledge from outside and for this purpose, we need to expose our thoughts to the world and try to get feedback. eg: This article)
There is however a zone which neither the self knows nor the public knows and this is what introduces a certain level of “Uncertainty” while designing “Privacy laws” and defining “Privacy”. Privacy Laws essentially tries to protect that aspect of human behaviour about which the individual himself is not aware but the Privacy Activists and the Courts sit in judgement thereof.
The Puttaswamy judgement is hailed as a “Landmark judgement in India”. But it only confirmed the known fact that “Privacy is a fundamental right of Indian citizens” but failed to define “Privacy”. (Refer the set of articles on this issue written earlier).
In the part of the discussions recorded in the judgement to which Justice D Y Chandrachud subscribed to, it was recognized that “Privacy is a State of Mind of an individual”. Hence the limitations of the law in designing a means of protecting the “State of Mind” was recognized and the focus of the judgement therefore remained only on “Information Privacy”.
The judgement also quoted “… privacy is the expectation that information about a person will be treated appropriately. This theory of “contextual integrity” believes people do not want to control their information or become inaccessible as much as they want their information to be treated in accordance with their expectation (Nissenbaum 2004, 2010, 2011)”
The judgement also recognized that “Privacy is the best friend of terrorists..” and there is a duty cast on the State to balance National Security even while designing Privacy laws.
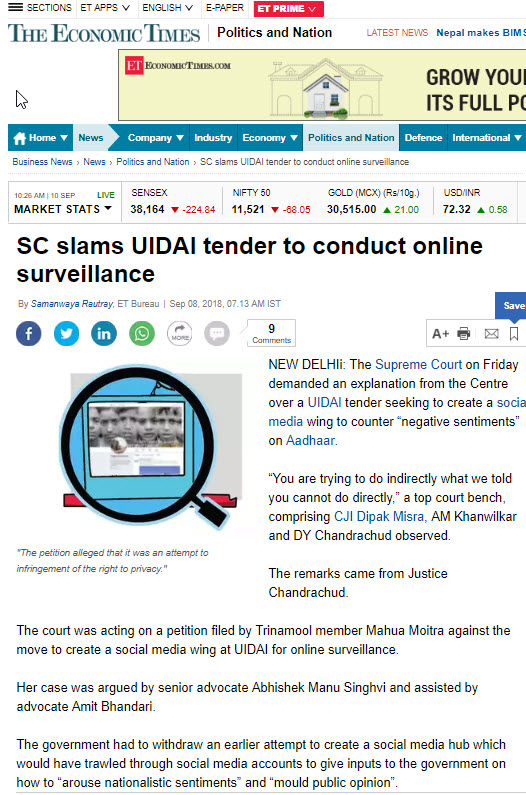
It is surprising that it is now the same judge D.Y.Chandrachud who is thinking that the RFP of UIDAI is likely to infringe on the Privacy of an individual. There is no doubt that he is being perhaps mislead by the petitioner’s advocates who are high profile politicians.
In our opinion it is the legitimate right and more appropriately the duty of UIDAI to know “What others know about itself but it itself does not know”. This is the “Blind Zone” in the Johari Window. It is the corporate wisdom that the authority takes all efforts to shrink this zone by trying to know what people are talking about itself.
As a citizen I would consider it the duty of UIDAI to monitor the media not only for its own reputation management but also to identify leads to potential attempts at hacking into different agencies and sub systems of Aadhaar. I believe this is what is attempted in the RFP.
“Surveillance” is the speculation which is in the minds of Mahua Moitra and Abhishek Manu Singhvi and is being transferred to the minds of the benches. The AG is not helping the judges arrive at a correct decision by refusing to point out to the judges that the perception that Mr Singhvi is trying to create is wrong and cannot be accepted. Perhaps he needs to be reminded of the story of the “Emperor’s new clothes”
AG by his silence is actually making the Court to come to a wrong conclusion. I wish the Communication industry professionals wake up and see what a wrong judgement in this case can do to their business.
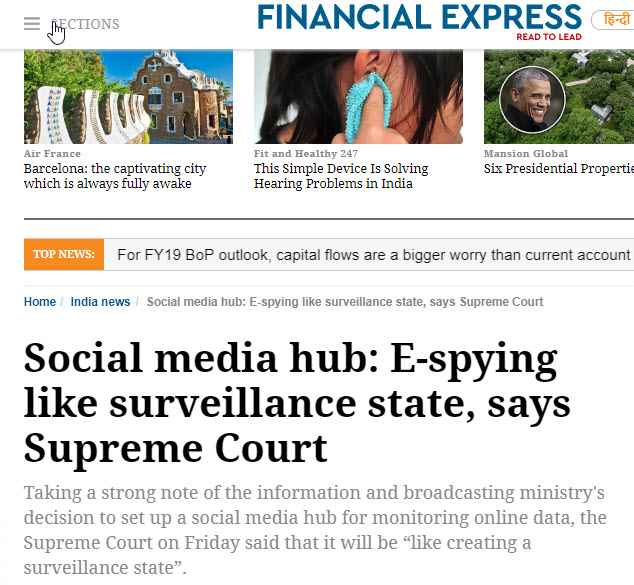
The way the discussions are progressing, the Court is likely accept that the current RFP is actually infringing on the privacy of the petitioner. If so, the activity envisaged in the RFP which we have called “Media Monitoring” will be deemed as equivalent to “Surveillance”.
By deduction therefore, in future, if any PR agency undertakes the task of News Paper Clipping services and monitoring social media on behalf of a Company, it would be termed illegal. The business of “Reputation management” will be illegal. The same way, the media monitoring by political parties including BJP and Congress both of whom maintain what they call “Media Monitoring Cells” will also become illegal.
If either of the political parties say they saw a news report and are reacting to it, the immediate counter would be “How did you know?…Did you monitor the Media?… Have you not given an undertaking to the Supreme Court that you would not do it?”
In this respect, Congress can continue to lie about everything because they have not given any undertaking to speak truth before the Court or the Public but if these lies are monitored by the I & B Ministry, Supreme Court will cry foul.
Presently, UIDAI is receiving threats from all over the world with motivated hackers trying to discredit the agency. It is not difficult to corrupt one or more of these Aadhaar user agencies, compromise their end point system either in collaboration or otherwise and then claim that UIDAI is compromised.
This is exactly what happened in the Abhinav Srivatsava incident where hospital systems were the source of access to UIDAI but it was called “hacking” of the UIDAI. It was the same case in respect of the Chandigarh journalist case and the more recent HuffpostIndia revelations.
Even Naavi.org has recently highlighted how the the e-KYC system can be misused because of the Aadhaar Authentication trusts the simple OTP over mobile as a means of authentication and enables Banking frauds to happen.
But these are not reasons to consider that this RFP is wrong. The security vulnerabilities are there in the Windows system itself and the way Internet is designed. All applications have to use appropriate security measures during the usage of the applications to reduce the risks. This applies to UIDAI as well as to others.
In order to understand what are the risks in the operation of any Company or an online service such as Aadhaar authentication, the Company has to carefully monitor the Internet and find out if any phishing websites or Apps have been in circulation, whether any of the citizens are experiencing any difficulties, whether there are any complaints registered under complaints.com or naavi.org or glassdoor.com etc.
Many times, it is the twitter and facebook which first reveals to the public that a particular vulnerability has been discovered. Before this, the deepweb would have discussed it and some hacks would be put on sale in the “Virus on Sale” list and these need to be monitored by a responsible agency.
Tomorrow if some body reports on a facebook page, that the Supreme Court judgement on its site can be modified and re-uploaded, Supreme Court should be the first agency which should watch out. That is “Media Monitoring” and not “Surveillance”.
It is regrettable that people want to mislead the public that the RFP of UIDAI is not media monitoring but is surveillance. Mr Singhvi is pointing out to the word “Listening” as one one of the specifications of the software. Let Mr Singhvi understand that there is some thing called Intrusion Detection Systems which often work along with Firewalls whose job is to “Listen” . The word “Listen” is used in the context of “Filtering” and not “Snooping”. Nevertheless, if internet packets going through a particular ISP system is “Listened to”, it may be a kind of snooping. But still it will be snooping into the corporate entity not subject to Privacy Rights but protected by the other laws.
Tomorrow, these advocates without technical background may interpret a “Handshake” between two systems as “Collaboration and Conspiracy and invoke Section 120 of IPC”!. Let us understand that techies have some terminologies that sound similar to popular words used elsewhere but have a different contextual meanings.
But what the RFP wants to do is not “Snooping into the packets” as they traverse the internet. It is scanning the published content ,from the published content identifying if the article is relevant for UIDAI and if so, list it out.
The Google Search Engine does exactly this. All robotic searches do the same. If a common Google search is termed as “Invasion of Privacy” of Mahua Moitra, and the Court wants to accept it, then the Court has to kill the internet itself.
Supreme Court cannot be selective and object only to UIDAI and I& B Ministry and block their need to monitor the media (Print, Electronic and online) without also blocking Google and other search engines as well as the Intrusion detection systems which are essential for protection against DDOS attacks.
If done, it will indicate that the Court is biased.
When does “Media Monitoring” becomes “Surveillance”? and infringe Privacy?
The dictionary definition of surveillance is:
“close observation, especially of a suspected spy or criminal.
eg: “he found himself put under surveillance by British military intelligence”
synonyms: observation, scrutiny, watch, view, inspection, monitoring, supervision, superintendence; spying, espionage, intelligence, undercover work, infiltration, reconnaissance; informal bugging, wiretapping, phone tapping, recon”leading members of the party were to be kept under surveillance”
The Cambridge dictionary definition is
“the careful watching of a person or place, especially by the police or army, because of a crime that has happened or is expected.
The essence of considering a Media Scanning as “Surveillance” is when an individual is tagged and the Government observes him, considering him as a potential criminal. If a Non Government entity does a similar act, we may call it as “Stalking”.
If a person is closely observed to the extent it creates harassment of the individual, then it becomes a ground for judicial intervention provided there is no prima facie reason to believe that the person is likely to endanger the national security.
If there is any “Suspicious” movement of a person in a street or in Cyber street, the Government not only has a reason for but also a duty to carry out “Surveillance”.Cyber Intelligence is part of the “Intelligence” activity that the Government intelligence agency has to undertake. if they are not doing it, they are committing dereliction of duty.
Now it is for the Supreme Court to read through the RFPs and identify if there is any “Surveillance” indicated. In the UIDAI RFP there is certainly nothing even closely remembering “Surveillance” and if Ms Moitra thinks so, it is the figment of her imagination.
The Supreme Court cannot undertake roving enquiries and conduct contentious litigation against the Government and paralyze Governance just to satisfy the ego of politicians working as advocates and looking for media sensitive bytes from the Judges to carry out their political agenda.
If the Supreme Court was serious, they should have called a media expert and checked if the RFP is meant to cause surveillance of the masses or some thing else.
I wish that the Public Relations Society of India impleads itself in the hearing and educates the Supreme Court.
Without considering the contents of the RFP and relying entirely on the pleadings of a petitioner, it is improper for the Supreme Court judges to pass comments in front of the press and allow the Press to pronounce as if “Supreme Court has slammed UIDAI”, “Supreme Court has called the RFP as E Spying” etc.
In our adversarial system of Jurisprudence, it is the responsibility of the defending counsel to highlight what all we are stating here.
I wish the AG brings home these points and let the Court come to a correct decision that RFP in question does not amount to Surveillance and there is no need for the Court to interfere in the day to day management of UIDAI. It is his duty to do so even if there is a possibility that the bench will hit back in the Aadhaar judgement which is now being held in reserve.
Fine should be imposed on the petitioner for bringing up a frivolous litigation and trying to mislead the Court. The petitioner’s advocates should be warned that they have to be more discrete in interpreting the commercial documents and consult relevant experts before jumping into conclusions and bringing it before the Court as truthful grounds for interference by the Court.
Naavi
P.S: EU parliament in the meantime seems to have passed a copyright rule which may mandate that internet platforms have to filter every piece of content from copyright angle. This means that the alternate presence of the content elsewhere in the Internet needs to be identified and the authorship also has to be tracked. Will this not be directly in conflict with what the above view of the Court may be suggesting? (Refer article here)