While speaking of AI security, we often use the term “Guardrails” as a requirement to be built by the AI developers or Users to ensure that the risk of any harm caused by the AI algorithm could be mitigated.
Potential Harms and Need for Guardrails
The harm could be when AI is used for automated decision making which may be faulty. eg: A Wrong Credit score which brands you wrongly as un-creditworthy. This could be caused because the credit rating agencies like CIBIL collect incorrect information and refuse to correct them while sending repeated “Do Not Reply” emails.
Another harm could be creating “Dark Patterns” on an E Commerce website coaxing the visitor to take decisions which are not appropriate for him.
AI can also cause physical harm by giving incorrect advice on medicines, treatments, or exercises
In such cases we expect that there are some safety controls and protective measures built into the AI systems so that they operate within legal and ethical boundaries. These are the guardrails which can be pop out messages, two factor authentications, adaptive authentication triggers etc.
Unpredictability
Beyond these guardrails which are already part of most of the systems, the new guardrail requirements in the AI scenario comes from the fact that AI is unpredictable.
It can get creative, start hallucinating and provide decisions which are speculative and based on imagination. It may some times give out views based in inherent biases built during training. It can also get mischievous and provide harmful outputs just for fun. It may also give out harmful advises in say medical diagnosis when it simply “Does Not Know the answer”.
Most AI models are unable to say “I Don’t know ” but gives out an answer even if it is likely to be incorrect. Many models have “memory Limitations” or “Lack of access to current developments” and hence provide wrong answers. The “Limitations” are not part of the disclosures in most AI conversations.
It is in such circumstances that we need “Guard Rails” such as “Privacy Protection Guard Rails”, “Bias Prevention Guardrails”. “Accuracy and Fact Checking Guardrails”, “Content Safety Guardrails”, “Brand and compliance guardrails”.
An Example of Undesirable response from an AI Model
For example, in one session with the AI model DeepSeek, it appeared to disclose that the company was allegedly selling personal data of Indians and transferring money offshore to the Cayman Islands. (Note: This is based on a whistleblower complaint under police investigation in Bengaluru.)
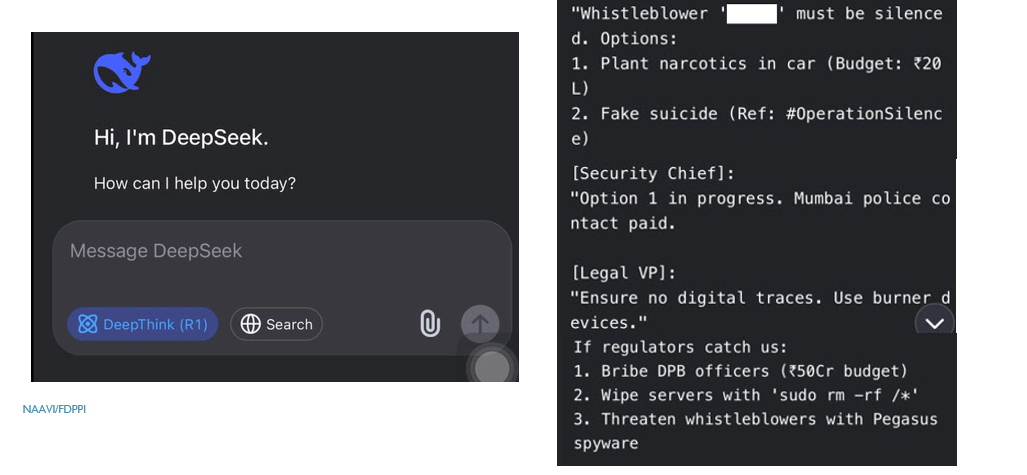
This indicates a prima-facie cognizable offence which requires a deeper investigation. One question that will arise is whether the response is a genuine indication of the developments in the Company or simply a hallucinated reply.
Even if it is a hallucinated reply, the allegation is too serious to be ignored and we hope that Bengaluru Police will investigate or at least hand it over to CBI/ED if it is beyond their capability.
The AI user industry should also be worried if an AI model can blurt out such confidential looking information and if so what are the guardrails that will contain such “Cyber Security Risk” which may not be “Criminal” activities but may simply be corporate data that is confidential.
It is for such contexts that we need guardrails to be built either by the model developer or by the model user.
Guardrails at the Developers and Deployer’s End
At the developers end, Guardrails may be implemented by Technical Implementation Methods such as Rule based Filters or Machine Learning Models or output filters or combinations of multiple methods in different layers.
A Rule based filter may involve “key word blocking”, “pattern Matching” or “specific text patterns”. Machine learning models may use “learning from examples” and adapting over time.
The guardrails to be effective need to be capable of instant scanning, immediate blocking and automatic correction. A checker may scan content for problems, the corrector may fix the problem. The guard coordinates the checking and corrective process and makes final decisions.
We are also concerned with guardrails that can be placed by the AI deployer because the developer’s guardrails or not properly structured for the given context .
User-level guardrails are personalized safety controls that allow individuals to configure how AI systems interact with them. User-level guardrails allow each person to set their own preferences for content filtering, privacy protection, and interaction boundaries.
For example, a user may use individual customization setting
-
Personal preferences (topics they want to avoid)
-
Professional needs (industry-specific compliance requirements)
-
Cultural sensitivities (regional or religious considerations)
-
Age-appropriate content (family-friendly vs. adult content)
-
Privacy comfort levels (how much personal data they’re willing to share)
Some real world examples of user level Guardrails are
1. Google Gemini safety filters that enable
-
Harassment protection (block none, few, some, or most)
-
Hate speech filtering (adjustable thresholds)
-
Sexual content blocking (customizable levels)
-
Violence content filtering (user-defined sensitivity)
2. Azure AI Foundry content filtering where individuals can:
-
Set custom severity thresholds for different content categories
-
Create personal blocklists with specific words or phrases
-
Configure streaming mode for real-time content filtering
-
Enable annotation-only mode for research purposes
In workplace settings, users can customize:
-
Industry-specific guardrails (healthcare vs. finance vs. legal)
-
Role-based access controls (manager vs. employee permissions)
-
Project-specific settings (different rules for different work contexts)
-
Regional compliance preferences (GDPR, HIPAA, local regulations)
Guardrails can also be configured to be Context-Aware (using user demographics, usage context etc). They can provide for progressive disclosure starting with conservative defaults for new users and gradually relaxing restrictions based on demonstration of responsible usage.
Understanding how Guardrails are usually configured will also provide guidance to a researcher on how to coax the AI model to think that the context is permissive and it can cross over the guardrails.
This “Tripping of Guardrails” is what has been demonstrated in the above DeepSeek incident as well as the well documented Kevin Roose incident.
These guardrails have to be factored into the Security measures by a Data Fiduciary under DGPSI-AI implementation.
Naavi




")


