Naavi.org has been highlighting that pending the passage of PDPB 2019 for whatever reason is a reason for the ongoing data loot that is happening in the country. The MobiKwik incident where 10 crore customer’s data has been stolen and posted on the darkweb is a manifestation of the negligence of Data Fiduciaries in implementing appropriate data security.
The large companies with millions of data are the targets of international data looters as we have seen in the case of Breach Candy hospital, Juspay, DrLal Pathlabs and now MobiKwik and this will continue.
While RBI has issued a notice now to MobiKwik, it is not known what RBI did in the case of Juspay or what CERT-In did in all these cases so far. It is fair to presume that they remained quiet and decided not to disturb the industry.
This is hypocrisy of these institutions.
To this list of “Facilitating Data Loot” through apathy, we should add four other instances of deliberate procrastination or inaction by the RBI, the Ministry of Finance and Ministry of IT as well as the honourable Supreme Court of India and the NASSCOM which have surfaced earlier.
They are
a) The Data loot by TransUnion through a secret and probably a fraudulent takeover of CIBIL in which RBI, the Ministry of Finance and a number of Indian Banks are involved.
b) The continued delay in passing the Banning of Crypto currencies bill which is the currency of the dark web and cyber criminals in which the Ministry of Finance and the Supreme Court are parties
c) The continued delay in passing of the PDPB 2019 in which the Ministry of IT is involved.
d) Move of Nasscom/DSCI to lobby for exclusion of financial data from the category of “Sensitive Personal Information” in the PDPB
The details of how CIBIL which was once owned by Indian Banks and in that context it was given a permission to exchange data of Bank customers for the purpose of “Prevention of bad debts” became part of a US commercial company has been documented in these columns earlier ( See here)
TransUnion-CIBIL is now a commercial “Credit Rating” company holding half a billion or more personal and financial data of Indian Citizens held and operated under the control of the US company in violation of the sovereignty principle applicable to data as an asset of the nation and the Data localization principle.
Inaccurate CIBIL data has put many customers in a “Credit Freeze” situation and is used for harassment by credit card companies as a threat to debt recovery.
Unfortunately the PDPB 2019 does not help us here since there is an “Exemption” for “Credit Rating” under the PDPB 2019 which can be misused by TransUnion-CIBIL or even MobiKwik to avoid penalties either for cross border transfer or for data breach.
But the PDPB 2019 2019 has a provision to define a “Significant Data Fiduciary” which can include a company like TransUnion CIBIL. But we have to wait and see if the JPC or the Parliament recognizes the need to put a regulatory framework on such companies.
Unfortunately, NASSCOM and DSCI which are expected to protect the interest of Indians and Indian data principals have taken the side of the business and are even putting pressure on MeitY to exclude “Financial Data” from the list of “Sensitive Personal Information” so that “Explicit Consent” and “Maintenance of a copy in India” does not apply to such processors of financial data.
Though Naavi has brought this to the notice of the JPC, we cannot be confident that the industry lobby may not prevail over the political masters.
We in Karnataka have repeatedly seen how the CM Mr Yeddyurappa often succumbs to the pressure tactics of the film industry so that people like Puneet Rajkumar can persuade the Government to take Covid Risks on the population because the “Yuva Ratna” has to make money. Mr Ravi Shankar Prasad may not be too different from Mr Yeddyurappa and would easily retract on hard decisions if sufficient pressure is applied. We need leaders with conviction and courage to take India out of the vicious circle that holds back the Government from taking hard decisions.
PDPB 2019 is still the hope that many in India hold for bringing some responsibility to the data fiduciaries. After the CIBIL experience and more so when the hackers first announce the hacking and even publish some data to later on retract and say that the data has been deleted etc., we can suspect that some of the Indian Companies who announce the data breach before they come under the PDPA radar, may actually be using the cover of a hacker to transfer their data to a foreign location.
This possibility could even be at the instance of the investors who have the managerial control of some of these Fintech start ups since the Government may not have a proper regulation for the investors to be insulated from data transfer related decisions. The PDPB 2019 does not have a mechanism to prevent say a Chinese investor asking for an audit by a Chinese firm as a part of its due diligence and in the process install a back door to facilitate further data loot.
But the delay in the passage of PDPB 2019 is an indication that until the business is ready and has successfully ported the personal data of all Indians as of date, PDPB 2019 would not be passed. Then like we say “Locking the stable after the horses have bolted”, Government may come up with PDPB 2019 as an Act.
In the meantime the continued procrastination by the Ministry of Finance in not passing the Banning of Crypto Currency is another indication that the Government of Mr Narendra Modi has weak points one of which is the Ministry of Finance. Even during the time of Mr Arun Jaitely, we had pointed out that the ministry is not taking the right decisions. This continues even now. Mr Subramanya Swamy has repeatedly pointed out the possibility of moles in the department who work for Mr Chidambaram more than Mr Modi and the decision not to kill the Bitcoin and Crypto currencies and also not initiate any action on CIBIL-Trans Union deal may be attributed to such a possibility.
I suspect that the PMO has been successfully kept in the dark about some of the above apprehensions and hence we are not getting any response from the Government to our frequent complaint dumps in the “Write to PMO” section of the PM s website or through the twitter handles.
Government perhaps only responds to political opponents and only if Rahul Gandhi or others make a comment, the issue is taken note of.
I would be happy to be proved wrong and Let’s hope that after the Bengal election at least, Mr Modi, Amit Shah and Mr Nadda get time to look into some of these issues which are eroding the confidence of the public in BJP and take remedial actions.
Naavi

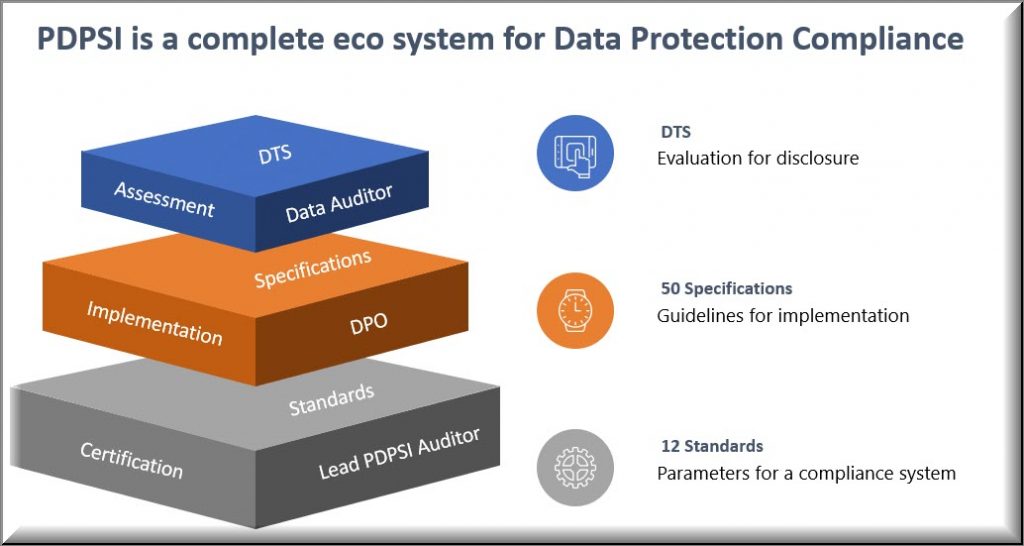 This PDPSI framework is not only a “Certifiable Audit Framework” like the ISO 27701 but also an Assessment framework for the Data Trust Score (DTS) system which is a representation of the Personal Data Protection maturity of an organization as assessed by an auditor using the 50 implementation specifications of the PDPSI framework.
This PDPSI framework is not only a “Certifiable Audit Framework” like the ISO 27701 but also an Assessment framework for the Data Trust Score (DTS) system which is a representation of the Personal Data Protection maturity of an organization as assessed by an auditor using the 50 implementation specifications of the PDPSI framework.






")


