Introduction
The banking sector occupies a unique position in the digital economy as one of the largest and most trusted repositories of personal information. Every banking transaction, starting from opening an account and completing Know Your Customer (KYC) formalities to availing loans, making digital payments, investing in financial products, or accessing internet and mobile banking services and many more, involves the continuous collection, processing, storage, and sharing of personal data, which are in digital form. Banks routinely handle a wide spectrum of information, including identity and demographic details, financial records, transaction histories, credit information, biometric identifiers, geo-location data, communication records, and behavioural data generated through digital channels. The rapid expansion of internet banking, mobile banking, Unified Payments Interface (UPI), digital wallets, artificial intelligence-driven customer services, cloud computing, open banking initiatives, and collaborations with fintech entities has significantly increased both the volume and sensitivity of digital personal data processed by banks.
While digital transformation has enhanced operational efficiency, financial inclusion, and customer convenience, it has simultaneously exposed banks to heightened risks arising from cyberattacks, ransomware, identity theft, phishing, financial fraud, insider threats, unauthorized profiling, and misuse of customer information. A single personal data breach[1] can compromise the privacy of millions of customers, disrupt essential banking services, invite intense regulatory scrutiny, expose the institution to substantial monetary penalties, and cause lasting reputational and financial harm. The recently reported incident involving the alleged exposure of approximately 1 TB of customer data of a leading Indian Bank on the dark web serves as a reminder of the increasing cybersecurity threats faced by financial institutions and reinforces the need for banks to adopt robust data governance and data protection frameworks. Consequently, safeguarding personal data has evolved from a purely technological concern into a core element of corporate governance, operational resilience, enterprise risk management, and customer trust.
Digital Personal Data Protection Act, 2023
Recognizing the need for a comprehensive legal framework governing digital personal data, Parliament enacted the Digital Personal Data Protection Act, 2023[2] (herein after DPDP Act or merely the Act), which received the assent of the President on 11 August 2023. To operationalise the Act, the Central Government subsequently notified the Digital Personal Data Protection Rules, 2025[3](DPDP Rules), together with a phased implementation schedule[4], providing Data Fiduciaries[5] adequate time to establish governance mechanisms, strengthen technological infrastructure, and align business processes with the statutory requirements. The Act establishes a rights-based framework for the processing of digital personal data while balancing the legitimate needs of businesses and the State. It introduces principles such as lawful processing, informed consent, purpose limitation, data minimisation, accuracy, storage limitation, reasonable security safeguards, accountability, and protection of the rights of Data Principals, thereby replacing the earlier fragmented regime under the Information Technology Act, 2000 and the Information Technology (Reasonable Security Practices and Procedures and Sensitive Personal Data or Information) Rules, 2011.
Implications DPDP Act for Banking Sector
The enactment of the DPDP Act has profound implications for the banking sector. Banks, by virtue of the nature, scale, and sensitivity of the personal data they process, will invariably qualify as Data Fiduciaries and many are likely to be notified as Significant Data Fiduciaries[6], (SDFs) thereby becoming subject to enhanced compliance obligations. The Act requires banks to redesign their data governance frameworks by embedding privacy-by-design principles into business operations, strengthening consent and notice management systems, implementing robust security safeguards, establishing effective grievance redressal mechanisms, ensuring timely reporting of personal data breaches, enforcing retention and deletion policies, and conducting periodic audits and Data Protection Impact Assessments (DPIA) where applicable. Compliance therefore extends well beyond traditional cybersecurity measures and necessitates integration of privacy governance into the institution’s overall governance, risk management, technology architecture, and regulatory compliance framework.
Against this backdrop, this article examines the implications of the DPDP Act for the banking sector by analysing the statutory compliance framework applicable to banks, the interplay between the Act and the existing regulatory regime administered by the Reserve Bank of India (RBI), and the principal legal, technological, and operational challenges confronting banks in implementing the new data protection framework. It also highlights practical measures necessary to achieve sustainable compliance while preserving customer trust, ensuring operational resilience, and supporting continued digital innovation in the financial sector.
Categories of Personal Data Processed by Banks
Banks routinely collect, process, and store a wide spectrum of personal data in the course of providing banking and financial services. This includes identity information such as the customer’s name, photograph, Permanent Account Number (PAN), Aadhaar number, passport, driving licence, and voter identification card, which are primarily used for KYC compliance and identity verification. They also process contact information, including residential and correspondence addresses, email addresses, and mobile phone numbers, to facilitate communication and account management. In addition, banks handle extensive financial information, comprising bank account details, deposits, loan accounts, credit histories, investment portfolios, insurance policies, and other financial assets and liabilities. Every banking transaction generates transactional data, such as payment histories, fund transfers, merchant payments, ATM withdrawals, UPI transactions, debit and credit card usage, and digital payment records. With the increasing adoption of digital banking, many institutions also process biometric data, including fingerprints, facial recognition, iris scans, and voice authentication, to strengthen customer authentication and prevent fraud.
Furthermore, banks collect information relating to customers’ digital behaviour, such as device identifiers, Internet Protocol (IP) addresses, login history, browser fingerprints, mobile banking application usage, and geolocation data. The aggregation and analysis of these diverse categories of personal data enable banks to create comprehensive financial and behavioural profiles of their customers, facilitating risk assessment, fraud detection, personalized financial services, and regulatory compliance. At the same time, the extensive nature of such data processing significantly heightens privacy and cybersecurity risks, making robust data governance, strict access controls, and compliance with the DPDP Act, essential for safeguarding customer information and maintaining public trust.
Banks as Significant Data Fiduciaries
Under the DPDP Act, banks unequivocally qualify as Data Fiduciaries because they determine the purpose and mean of processing the personal data of their customers, employees, and other stakeholders. Virtually every banking function involves the collection, storage, use, sharing, and retention of digital personal data. This includes customer onboarding and KYC verification, operation of savings and current accounts, credit card services, internet and mobile banking, digital payments, customer relationship management, and regulatory reporting and many more listed in the earlier para. In addition to customer data, banks also process personal information relating to employees, directors, shareholders, vendors, business correspondents, guarantors, nominees, beneficiaries, and other associated persons. The volume, diversity, and sensitivity of this information place banks among the largest repositories of personal data in the country.
Given the enormous scale of personal data processed, the critical role of banks in the financial system, and the potential impact of any data breach on millions of individuals and the economy, many banks, particularly public sector banks, large private sector banks, payment banks, and systemically important financial institutions, are likely to be notified by the Central Government as SDFs[7] under Section 10 of the DPDP Act.
Designation as a SDFs carries additional compliance obligations beyond those applicable to ordinary Data Fiduciaries. These include the appointment of a Data Protection Officer (DPO)[8] based in India to oversee compliance and act as the point of contact for Data Principals and the Data Protection Board[9] of India(DPBI), the appointment of an Independent Data Auditor[10] to periodically assess compliance, the conduct of DPIAs for high-risk processing activities, periodic compliance audits, implementation of comprehensive risk management measures, and the adoption of enhanced technical and organizational safeguards to ensure privacy by design and data security. SDFs are also expected to maintain robust governance mechanisms, continuously monitor privacy risks, strengthen vendor oversight, and establish effective systems for incident response, breach reporting, and grievance redressal.
Accordingly, the banking sector occupies a unique position under the DPDP framework. Compliance extends far beyond safeguarding information through cybersecurity measures; it requires the establishment of a comprehensive data governance framework that embeds the principles of lawfulness, transparency, accountability, purpose limitation, data minimization, storage limitation, and respect for the rights of Data Principals into every aspect of banking operations. As banks continue to embrace digital transformation, artificial intelligence, cloud computing, and fintech partnerships, fulfilling these enhanced obligations will be essential not only for statutory compliance but also for preserving customer confidence, financial stability, and trust in India’s digital banking ecosystem.
Major Obligations of Banks under the DPDP Act
The DPDP Act, imposes a comprehensive set of obligations on banks to ensure that personal data is processed in a lawful, transparent, secure, and accountable manner. As Data Fiduciaries, banks are required to adopt robust governance practices throughout the data lifecycle, from collection and use to storage and deletion. These obligations are designed to protect the privacy rights of customers while promoting responsible data management and regulatory compliance. Effective implementation of these requirements is essential for maintaining customer trust, strengthening cybersecurity, and fostering a resilient digital banking ecosystem.
Notice and Consent Management
One of the foundational obligations imposed on banks under the DPDP Act, is to ensure transparency in the collection and processing of personal data through a legally compliant notice and consent framework. Section 5 of the DPDP Act mandates that every request for consent must be preceded by, or accompanied with, a clear and standalone notice informing the ‘Data Principal’[11] about the personal data proposed to be collected, the specific purpose for which it is to be processed, the manner in which the Data Principal may exercise the rights available under the Act, the procedure for making complaints to the Data Protection Board, and the method for withdrawing consent. Such notice must be presented in clear and plain language, be easily understandable, and, wherever feasible, be made available in English as well as the languages specified in the Eighth Schedule to the Constitution. For banks, this requires replacing lengthy legal disclaimers and complex privacy policies with concise, customer-friendly privacy notices that enable customers to make informed decisions regarding the processing of their personal data.
Closely linked to the notice requirement is the obligation to obtain valid consent for processing personal data. Section 6[12] of the DPDP Act provides that consent must be free, specific, informed, unconditional, unambiguous, and signify a clear affirmative action by the Data Principal. Banks must therefore ensure that consent is obtained separately for each distinct purpose and avoid the practice of bundled or blanket consent, whereby customers unknowingly authorize multiple unrelated processing activities through a single acceptance.
While processing that is necessary for opening and operating bank accounts, complying with KYC norms, anti-money laundering obligations, or other statutory requirements may fall within the category of legitimate uses[13] under Section 7, activities such as sending promotional or marketing communications, sharing customer information with group companies or affiliates for commercial purposes, AI-driven customer profiling, cross-selling insurance or investment products, or disclosing customer data to fintech partners generally require separate and explicit consent.
The Act further guarantees that the Data Principal has the right to withdraw consent at any time, and such withdrawal must be as simple and accessible as the mechanism through which consent was originally provided. Consequently, banks are required to establish robust consent management systems capable of recording, updating, tracking, and honouring customer consent preferences throughout the lifecycle of personal data processing.
Purpose Limitation and Data Minimization
The principles of purpose limitation and data minimization are central to the DPDP Act, and require banks to adopt a disciplined approach to the collection and processing of personal data. Banks are permitted to collect and process only such personal data as is necessary for specified, lawful, and legitimate purposes. For example, collecting a customer’s PAN for compliance with income tax laws or obtaining KYC documents for account opening is fully justified; however, collecting information such as customers’ social media profiles without a legitimate necessity, or reusing KYC documents for unrelated marketing or promotional activities without obtaining fresh consent, would be inconsistent with the principle of purpose limitation.
Complementing this requirement is the principle of data minimization, which obligates banks to periodically review the nature and extent of the personal data they collect and retain. Many banks continue to rely on legacy application forms and business processes that capture excessive or redundant customer information. The DPDP Act therefore requires institutions to assess whether every data field collected is genuinely necessary for the intended purpose, eliminate duplicate or superfluous information, and determine whether historical records continue to serve any legal, regulatory, or operational purpose. By limiting data collection to what is relevant and necessary, banks can streamline customer onboarding, improve data quality, reduce storage costs, minimize privacy and cybersecurity risks, and strengthen overall compliance with the DPDP framework.
Security Safeguards and Storage Limitation
The DPDP Act, places a statutory obligation on banks to ensure the security of personal data throughout its lifecycle. Section 8(5) mandates that every Data Fiduciary shall protect personal data in its possession or under its control by implementing reasonable security safeguards to prevent personal data breaches. For banks, this requires the adoption of a comprehensive information security framework encompassing technical, administrative, and physical controls.
Technical safeguards include strong encryption of data at rest and in transit, multi-factor authentication, network segmentation, Security Operations Centres (SOCs), intrusion detection and prevention systems, endpoint protection, continuous vulnerability assessments, and real-time monitoring of cyber threats. Administrative measures involve the formulation of robust privacy and information security policies, periodic employee awareness and training programmes, vendor due diligence, contractual safeguards for third-party service providers, internal compliance audits, and effective incident response mechanisms. Physical safeguards include access-controlled data centres, secure archival facilities, CCTV surveillance, visitor management systems, environmental controls, and protection against unauthorized physical access. Given the rapidly evolving nature of cyber threats, including ransomware, phishing, insider attacks, and sophisticated cyber intrusions, banks must continuously review and upgrade their security controls to ensure resilience against emerging risks.
Equally important is the principle of storage limitation, embodied in Section 8(7) of the DPDP Act, which requires a Data Fiduciary to erase personal data as soon as the purpose for which it was collected has been fulfilled and its retention is no longer necessary for compliance with any applicable law. Accordingly, banks cannot retain customers’ personal data indefinitely merely because it may prove useful in the future. Instead, they must establish well-defined data retention and disposal policies that are harmonized with statutory and regulatory requirements under the RBI Directions, the Income-tax Act, 1961, the Prevention of Money Laundering Act (PMLA), 2002, the Companies Act, 2013, applicable evidentiary requirements, and contractual obligations. Upon the expiry of the prescribed retention period and in the absence of any continuing legal requirement, personal data should be securely erased, anonymized, or irreversibly destroyed using appropriate technical methods. Adherence to these principles not only ensures compliance with the DPDP Act but also minimizes privacy risks, reduces unnecessary storage costs, limits the impact of potential data breaches, and strengthens customer confidence in the banking system.
Rights of Banking Customers and Accuracy of Personal Data
The DPDP Act, establishes a robust rights-based framework that empowers banking customers, as Data Principals, while simultaneously imposing corresponding obligations on banks as Data Fiduciaries. Under Section 11[14], customers have the right to obtain information regarding the personal data being processed about them, including a summary of such personal data, the processing activities undertaken, the identities or categories of Data Fiduciaries and Data Processors with whom the data has been shared, and any other information prescribed under the Act. This enhances transparency and enables customers to understand how their personal information is being used.
Further, Section 12[15] confers the right to correction, completion, updating, and erasure of personal data. Accordingly, banks must establish efficient mechanisms to enable customers to rectify inaccurate or incomplete information, update addresses, contact details, nominee particulars, and other relevant records, thereby ensuring that customer data remains accurate, complete, and current. Maintaining accurate personal data is also a statutory obligation of banks under Section 8, as inaccuracies may result in failed transactions, erroneous credit assessments, regulatory non-compliance, financial losses, and customer disputes. Consequently, banks should implement periodic verification and updating mechanisms to preserve the integrity and reliability of customer information.
The right to erasure, however, is not absolute. While customers may seek deletion of their personal data once the purpose of processing has been fulfilled, banks must balance this right against their statutory obligations to retain records under various laws, including the Reserve Bank of India Act, the Banking Regulation Act, 1949, the Prevention of Money Laundering Act, 2002, the Income-tax Act, 1961, and other applicable regulatory and evidentiary requirements.
In addition, Section 13[16] mandates that every Data Fiduciary establish an effective ‘grievance redressal mechanism’, enabling customers to raise concerns regarding the processing of their personal data. If a grievance remains unresolved after exhausting the bank’s internal mechanism, the customer may approach the DPBI for appropriate relief in accordance with the Act.
The DPDP Act also introduces, under Section 14[17], the ‘right to nominate’, permitting a Data Principal to nominate another individual to exercise his or her rights under the Act in the event of death or incapacity. Banks must therefore incorporate this statutory nomination facility into their privacy governance and customer relationship management systems. Collectively, these provisions reinforce the principles of transparency, accountability, and customer empowerment, while requiring banks to establish comprehensive data governance practices that respect individual privacy rights without compromising statutory and regulatory compliance.
Responsibilities of Banks in Relation to Data Processors
The increasing digitization of banking services has led banks to extensively outsource a wide range of operational and technological functions to third-party service providers, including cloud service providers, payment gateways, call centres, collection agencies, fintech partners, software vendors, data analytics companies, and other technology service providers. Under the DPDP, these entities ordinarily function as Data Processors[18], processing personal data on behalf of the bank, which continues to remain the Data Fiduciary. Section 8(2) of the DPDP Act expressly provides that where a Data Fiduciary engages a Data Processor to process personal data on its behalf, the Data Fiduciary shall remain responsible for ensuring compliance with the provisions of the Act in respect of such processing. Consequently, banks cannot absolve themselves of their statutory obligations merely because the processing activity has been outsourced. They are required to exercise appropriate due diligence before engaging third-party processors and to ensure that such entities implement adequate technical and organizational measures to protect personal data from unauthorized access, disclosure, alteration, loss, or misuse. To ensure accountability, contractual arrangements with Data Processors should clearly define the scope and purpose of processing and incorporate comprehensive provisions relating to confidentiality, information security obligations, compliance with applicable laws, audit and inspection rights, timely notification of personal data breaches, restrictions on sub-processing, secure deletion or return of personal data upon termination of the contract, data retention requirements, business continuity and disaster recovery measures, and cooperation during regulatory investigations or audits. Banks should also undertake periodic risk assessments, security audits, and compliance reviews of their Data Processors to ensure continued adherence to the DPDP Act and other sector-specific regulatory requirements issued by the Reserve Bank of India. Given the growing reliance on outsourced digital infrastructure and cloud-based services, effective oversight of Data Processors has become an indispensable component of the privacy governance and risk management framework of every banking institution.
Personal Data Breach Management and Technology Transformation
In an increasingly digital banking environment, the protection of personal data against cyber threats has become a critical statutory obligation under the Act. Banks are continually exposed to sophisticated cyber risks, including phishing attacks, ransomware, malware, insider threats, credential theft, supply-chain compromises, distributed denial-of-service (DDoS) attacks, and other forms of cyber intrusion that may result in unauthorized access to or disclosure of customers’ personal data. Recognizing these risks, Section 8(6) of the DPDP Act requires every Data Fiduciary to notify the Data Protection Board of India and each affected Data Principal in the event of a personal data breach, in such form and manner as may be prescribed. The DPDP Rules, 2025 further prescribe the procedures, timelines, and contents of such breach notifications. Accordingly, banks must establish a comprehensive incident response and breach management framework capable of promptly detecting, containing, investigating, and mitigating security incidents. Such a framework should include continuous security monitoring, timely containment of compromised systems, forensic investigation, assessment of the nature and extent of the breach, prompt notification to affected customers and regulatory authorities, root-cause analysis, corrective and preventive actions, restoration of normal operations, and periodic post-incident reviews to strengthen organizational resilience against future attacks.
Compliance with the DPDP Act also necessitates a fundamental transformation of banking technology infrastructure and data governance practices. Traditional core banking systems, many of which were designed primarily for operational efficiency rather than privacy compliance, must now be modernized to support the lifecycle management of personal data. Banks should deploy integrated technological solutions for consent lifecycle management, centralized consent repositories, privacy dashboards, automated data retention and deletion, enterprise-wide data discovery and classification, identity and access governance, comprehensive audit trails, and automated compliance monitoring. Institutions designated as Significant Data Fiduciaries should also implement systems to facilitate Data Protection Impact Assessments (DPIAs), privacy risk assessments, and periodic compliance audits as required under Section 10 of the Act. Furthermore, as banks increasingly adopt artificial intelligence and machine learning for credit assessment, fraud detection, customer service, and personalized financial products, such technologies must be developed and deployed in accordance with the principles of privacy by design, transparency, accountability, and fairness. AI systems should incorporate appropriate safeguards to prevent unauthorized profiling, discriminatory decision-making, excessive data collection, and algorithmic bias, thereby ensuring that technological innovation remains aligned with the privacy rights guaranteed under the DPDP Act.
Implementation Challenges
The principal compliance and implementation challenges faced by banks under the DPDP Act may be analysed under the following broad themes:
- Legacy Banking Infrastructure – Modernising decades-old core banking systems to support consent management, purpose limitation, storage limitation, and automated deletion in accordance with Sections 5, 6, and 8.
- Regulatory Harmonisation – Aligning obligations under the DPDP Act with existing regulatory frameworks, including the RBI Act, 1934, the Banking Regulation Act, 1949, the PMLA, 2002, the Information Technology Act, 2000, the RBI Master Direction on KYC, the Payment and Settlement Systems Act, 2007, and the Credit Information Companies (Regulation) Act, 2005. Particular challenges arise where statutory record-retention requirements appear to conflict with the right to erasure under Section 12.
- Consent Management – Distinguishing processing based on consent under Sections 5 and 6 from “legitimate uses” under Section 7 while managing multiple banking products, digital platforms, and customer interactions across diverse delivery channels.
- Third-Party and Cloud Governance – Since banks remain accountable under Section 8(2) for the acts and omissions of Data Processors, including cloud service providers, fintech partners, payment aggregators, and outsourced service providers, they must implement robust contractual safeguards, vendor due diligence, periodic audits, and continuous oversight.
- Cybersecurity and Data Breach Response – Compliance with Sections 8(5) and 8(6) requires sustained investment in cybersecurity infrastructure, Security Operations Centres (SOCs), encryption, incident response capabilities, digital forensics, and timely breach detection and notification mechanisms.
- Artificial Intelligence and Algorithmic Governance – The growing use of AI in credit scoring, fraud detection, customer profiling, and risk assessment necessitates strong governance frameworks to ensure transparency, explainability, fairness, bias mitigation, accountability, and privacy by design, particularly for Significant Data Fiduciaries under Section 10.
- Data Governance and Enterprise Data Integration – Customer information is often dispersed across core banking systems, mobile applications, payment platforms, loan management systems, and legacy databases, making enterprise-wide data mapping, classification, quality assurance, and lifecycle management a significant operational challenge.
- Cross-Border Data Transfers – Banks engaged in international banking, correspondent banking, SWIFT transactions, overseas branch operations, and global cloud-based services routinely transfer personal data across jurisdictions. Compliance requires such transfers to satisfy restrictions notified by the Central Government while also meeting applicable foreign data protection laws, contractual commitments, and international regulatory requirements. Managing these overlapping obligations presents substantial legal, operational, and compliance challenges.
- Human Resource and Organisational Readiness – Effective implementation demands organisation-wide privacy awareness, specialised employee training, clearly defined accountability structures, appointment of Data Protection Officers and independent Data Auditors for Significant Data Fiduciaries, and the development of a strong privacy culture.
- Governance, Board Oversight, and Regulatory Uncertainty – Successful implementation requires banks to integrate privacy and data protection into their enterprise risk management and corporate governance frameworks. Consistent with the RBI’s emphasis on Board-level oversight of technology, cybersecurity, and operational resilience, banks must establish clear governance structures, allocate accountability, and ensure continuous monitoring through audits and compliance reviews. Simultaneously, evolving regulatory guidance, emerging enforcement practices of the Data Protection Board of India, and future judicial interpretations necessitate adaptive compliance frameworks capable of responding to changing legal and regulatory expectations.
- Financial Cost of Compliance – Investment in privacy management platforms, consent repositories, DPIAs, encryption, identity and access management, audits, vendor governance, and legacy system modernisation can impose significant financial burdens, particularly on cooperative banks, regional rural banks, and smaller financial institutions.
- Data Retention, Localisation, and Deletion – Banks must reconcile the Act’s principles of storage limitation and erasure with statutory record-retention obligations under the PMLA, 2002, the Banking Regulation Act, 1949, RBI Master Directions, and other financial sector regulations. Additional complexity arises where foreign laws, international regulatory requirements, or contractual commitments mandate different retention periods or storage locations, making legally compliant retention and deletion policies particularly challenging.
- Customer Awareness and Trust – Effective implementation also depends on educating customers about their rights under Sections 11 to 14, including the rights to access, correction, completion, updating, erasure, grievance redressal, and nomination. Banks must establish transparent and user-friendly mechanisms for handling customer requests, maintaining accurate records, responding to grievances within prescribed timelines, and demonstrating compliance through effective governance and documentation.
Taken together, these challenges emphasise that compliance with the DPDP Act extends far beyond information security or technical safeguards. It requires an enterprise-wide governance framework integrating legal compliance, technology, risk management, business operations, and customer-centric privacy practices. Banks must therefore balance statutory obligations, operational efficiency, technological innovation, and customer trust while embedding privacy and data protection into their overall governance architecture.
Integration of Regulations and Practices for Implementation
The implementation of the DPDP Act in the banking sector cannot be viewed in isolation, as banks operate within a comprehensive and well-established regulatory framework governing financial stability, customer protection, anti-money laundering measures, payment systems, and cybersecurity. Consequently, the DPDP Act must be harmoniously integrated with various sector-specific statutes and regulatory directions. While the DPDP Act seeks to protect the privacy rights of Data Principals by regulating the collection, processing, storage, and disclosure of personal data, these banking laws simultaneously impose statutory obligations on banks to collect, verify, retain, and disclose customer information for regulatory supervision, anti-money laundering compliance, fraud prevention, tax administration, and law enforcement purposes. Accordingly, banks must carefully reconcile the privacy rights conferred under the DPDP Act—particularly those relating to notice, consent, correction, erasure, and data retention under Sections 5, 6, 8, and 12—with mandatory disclosure and record-retention requirements prescribed under other applicable laws. Such harmonization requires a carefully designed governance framework that ensures statutory compliance without compromising the privacy and data protection rights of customers.
To achieve sustainable compliance with the DPDP Act, banks should adopt a comprehensive enterprise-wide privacy governance framework founded on the principles of accountability, transparency, privacy by design, and risk-based data management. In accordance with the obligations imposed upon Data Fiduciaries under Section 8 and the enhanced responsibilities applicable to SDF under Section 10, banks should establish dedicated data governance and privacy committees to oversee compliance, formulate internal privacy policies, and periodically review organizational practices. Regular enterprise-wide data discovery, data mapping, and data classification exercises should be undertaken to identify personal data repositories, monitor data flows, and maintain accurate records of processing activities and customer consent. Privacy-by-design principles should be embedded into the development of new banking products, digital channels, and financial technologies, supported by strong technical safeguards such as encryption, tokenization, pseudonymization, identity and access management, and comprehensive audit trails. Banks designated as Significant Data Fiduciaries should conduct DPIAs for high-risk processing activities, appoint an independent Data Auditor, and ensure continuous oversight by the DPO. Equally important are robust third-party risk management frameworks incorporating vendor due diligence, contractual safeguards, and periodic compliance audits of Data Processors, as required under Section 8(2). Privacy governance should also be seamlessly integrated with cybersecurity, operational resilience, business continuity planning, and incident response mechanisms to ensure preparedness against personal data breaches and cyber threats. Through such a holistic and integrated approach, banks can simultaneously fulfil their statutory obligations under the DPDP Act and sectoral banking regulations while strengthening customer trust, operational resilience, and the overall integrity of India’s digital financial ecosystem.
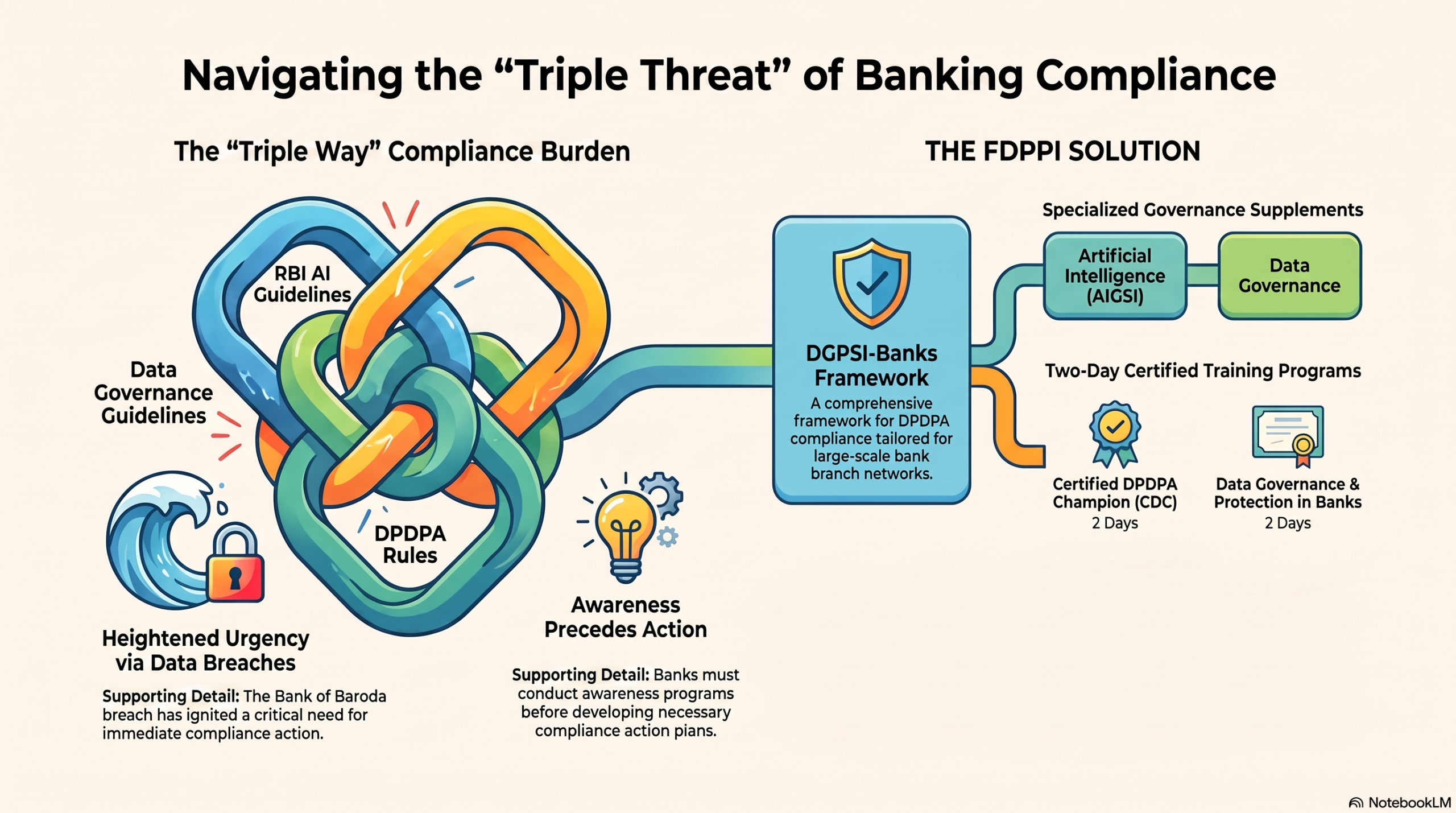
Suitability of DGPSI in Compliance Standards in Banks
Banks operate within a highly regulated environment governed by multiple legal and regulatory frameworks issued by the RBI, Meity and emerging AI governance requirements. While these frameworks provide extensive controls for information security and risk management, they do not comprehensively address the privacy-centric obligations introduced by the DPDP Act. Consequently, banks face the challenge of harmonising DPDPA requirements with existing regulatory obligations without creating duplication or compliance gaps. In this context, the Data Governance and Protection Standard of India (DGPSI) offers a comprehensive privacy governance framework that aligns DPDPA compliance with established information security and governance practices. By integrating consent management, purpose limitation, data minimisation, retention, breach management, accountability, and privacy-by-design principles, DGPSI can serve as an effective compliance standard that complements RBI’s regulatory framework while facilitating demonstrable DPDPA compliance in the banking sector. For specific details reference be made to article ‘DPDPA Compliance in a heavily regulated sector like Banks[19]’, Posted on July 13, 2026 by Vijaya Shankar Na.
The Way Forward and Conclusion
The DPDP Act marks a fundamental shift in India’s regulatory approach to personal data—from a compliance-oriented regime to a framework founded on customer-centric privacy governance, accountability, and responsible data stewardship. For the banking sector, compliance with the Act extends far beyond meeting statutory obligations; it requires embedding privacy into every aspect of governance, technology, business processes, and organizational culture.
By adopting comprehensive privacy management frameworks, appointing competent DPOs, conducting DPIAs, strengthening vendor oversight, implementing privacy-enhancing technologies, and fostering a culture of accountability and continuous employee awareness, banks can effectively balance regulatory compliance with innovation. Ultimately, institutions that recognize personal data as a valuable asset held in trust for their customers, rather than merely as a commercial resource, will be best positioned to safeguard the fundamental right to privacy, reinforce customer confidence, improve data quality and cybersecurity, and contribute to a secure, transparent, and resilient digital banking ecosystem. In this sense, the DPDP Act represents not only a transformative legal framework for data protection but also a catalyst for responsible digital transformation and sustainable growth in the Indian banking sector.
Mr. M. G. Kodandaram, IRS.
Assistant Director (Retd)
ADVOCATE and CONSULTANT
[1] DPDP Act – Sec 2 (u) “personal data breach” means any un-authorised processing of personal data or accidental disclosure, acquisition, sharing, use, alteration, destruction or loss of access to personal data, that compromises the confidentiality, integrity or availability of personal data;
[2] https://www.meity.gov.in/static/uploads/2024/06/2bf1f0e9f04e6fb4f8fef35e82c42aa5.pdf
[3] Meity Notification No. G.S.R. 846(E), dated 13 November 2025
[4] Meity Notification No. G.S.R. 843(E), dated 13 November 2025
[5] DPDP Act – Sec 2 (i) “Data Fiduciary” means any person who alone or in conjunction with other persons determines the purpose and means of processing of personal data;
[6] DPDP Act – Sec (z) “Significant Data Fiduciary” means any Data Fiduciary or class of Data Fiduciaries as may be notified by the Central Government under section 10;
[7] DPDP Act – Sec 10. Additional obligations of Significant Data Fiduciary. (1) The Central Government may notify any Data Fiduciary or class of Data Fiduciaries as Significant Data Fiduciary, on the basis of an assessment of such relevant factors as it may determine, including— (a) the volume and sensitivity of personal data processed; (b) risk to the rights of Data Principal; (c) potential impact on the sovereignty and integrity of India; (d) risk to electoral democracy; (e) security of the State; and (f) public order. (2) The Significant Data Fiduciary shall— (a) appoint a Data Protection Officer who shall— (i) represent the Significant Data Fiduciary under the provisions of this Act; (ii) be based in India; (iii) be an individual responsible to the Board of Directors or similar governing body of the Significant Data Fiduciary; and (iv) be the point of contact for the grievance redressal mechanism under the provisions of this Act; (b) appoint an independent data auditor to carry out data audit, who shall evaluate the compliance of the Significant Data Fiduciary in accordance with the provisions of this Act; and (c) undertake the following other measures, namely:— (i) periodic Data Protection Impact Assessment, which shall be a process comprising a description of the rights of Data Principals and the purpose of processing of their personal data, assessment and management of the risk to the rights of the Data Principals, and such other matters regarding such process as may be prescribed; (ii) periodic audit; and (iii) such other measures, consistent with the provisions of this Act, as may be prescribed.
[8] DPDP Act – Sec2 (l) “Data Protection Officer” means an individual appointed by the Significant Data Fiduciary under clause (a) of sub-section (2) of section 10;
[9]DPDP Act – Sec2 (c) “Board” means the Data Protection Board of India established by Central Government under sec 18;
[10] https://aidai.org.in/wp/
[11] DPDP Act – Sec 2 (j) “Data Principal” means the individual to whom the personal data relates and where such individual is— (i) a child, includes the parents or lawful guardian of such a child; (ii) a person with disability, includes her lawful guardian, acting on her behalf;
[12] DPDP Act – Sec 6. Consent (1) The consent given by the Data Principal shall be free, specific, informed, unconditional and unambiguous with a clear affirmative action, and shall signify an agreement to the processing of her personal data for the specified purpose and be limited to such personal data as is necessary for such specified purpose.
[13] DPDP Act – Sec 7. Certain legitimate uses.
[14] DPDP Act – Sec 11. Right to access information about personal data. (1) The Data Principal shall have the right to obtain from the Data Fiduciary to whom she has previously given consent, including consent as referred to in clause (a) of section 7 (hereinafter referred to as the said Data Fiduciary), for processing of personal data, upon making to it a request in such manner as may be prescribed,— (a) a summary of personal data which is being processed by such Data Fiduciary and the processing activities undertaken by that Data Fiduciary with respect to such personal data; (b) the identities of all other Data Fiduciaries and Data Processors with whom the personal data has been shared by such Data Fiduciary, along with a description of the personal data so shared; and (c) any other information related to the personal data of such Data Principal and its processing, as may be prescribed. (2) Nothing contained in clause (b) or clause (c) of sub-section (1) shall apply in respect of the sharing of any personal data by the said Data Fiduciary with any other Data Fiduciary authorised by law to obtain such personal data, where such sharing is pursuant to a request made in writing by such other Data Fiduciary for the purpose of prevention or detection or investigation of offences or cyber incidents, or for prosecution or punishment of offences.
[15] DPDP Act – Sec 12. Right to correction and erasure of personal data. (1) A Data Principal shall have the right to correction, completion, updating and erasure of her personal data for the processing of which she has previously given consent, including consent as referred to in clause (a) of section 7, in accordance with any requirement or procedure under any law for the time being in force. (2) A Data Fiduciary shall, upon receiving a request for correction, completion or updating from a Data Principal, — (a) correct the inaccurate or misleading personal data; (b) complete the incomplete personal data; and (c) update the personal data. (3) A Data Principal shall make a request in such manner as may be prescribed to the Data Fiduciary for erasure of her personal data, and upon receipt of such a request, the Data Fiduciary shall erase her personal data unless retention of the same is necessary for the specified purpose or for compliance with any law for the time being in force.
[16] DPDP Act – Sec 13. Right of grievance redressal. (1) A Data Principal shall have the right to have readily available means of grievance redressal provided by a Data Fiduciary or Consent Manager in respect of any act or omission of such Data Fiduciary or Consent Manager regarding the performance of its obligations in relation to the personal data of such Data Principal or the exercise of her rights under the provisions of this Act and the rules made thereunder. (2) The Data Fiduciary or Consent Manager shall respond to any grievances referred to in sub-section (1) within such period as may be prescribed from the date of its receipt for all or any class of Data Fiduciaries. (3) The Data Principal shall exhaust the opportunity of redressing her grievance under this section before approaching the Board.
[17] DPDP Act – 14. Right to nominate. (1) A Data Principal shall have the right to nominate, in such manner as may be prescribed, any other individual, who shall, in the event of death or incapacity of the Data Principal, exercise the rights of the Data Principal in accordance with the provisions of this Act and the rules made thereunder. (2) For the purposes of this section, the expression “incapacity” means inability to exercise the rights of the Data Principal under the provisions of this Act or the rules made thereunder due to unsoundness of mind or infirmity of body
[18] DPDP Act – Sec 2 (k) “Data Processor” means any person who processes personal data on behalf of a Data Fiduciary;
[19] Read ‘DPDPA Compliance in a heavily regulated sector like Banks’, by Vijaya Shankar Na at
https://www.naavi.org/wp/dpdpa-compliance-in-a-heavily-regulated-sector-like-banks/







")


